
在本教程的第一部分中,我们将概述强化学习中的关键概念,涵盖神经科学和机器学习中的RL的历史。我们将从早期的奖励动机行为的基本模型开始,因为它们应用于动物和机器学习。我们将讨论这些模型如何通过与丰富的特征和结构化世界模型的接口变得更加丰富,以及这些方法如何应用于复杂行为的分析和神经计算。**最后,我们将讨论这些想法如何在深度RL中最先进的方法中体现出来。**在本教程的后半部分,我们将进行一个编码练习,对RL智能体进行编码,并提取激活值,以与神经活动进行比较。

Kimberly Stachenfeld是DeepMind的研究科学家。她的研究涵盖了计算神经科学和机器学习的主题,并专注于如何学习结构化的、具有表现力的世界模型的一般问题,以实现灵活的推理。在机器学习中,她对使用图神经网络学习的前向模型的方法和应用特别感兴趣,在神经科学中,她主要研究高效、可扩展的强化学习的海马体表示数学模型。她于2018年获得普林斯顿大学计算神经科学博士学位,以及学士/学士学位2013年毕业于塔夫茨大学数学/化学和生物工程专业。






成为VIP会员查看完整内容
相关内容

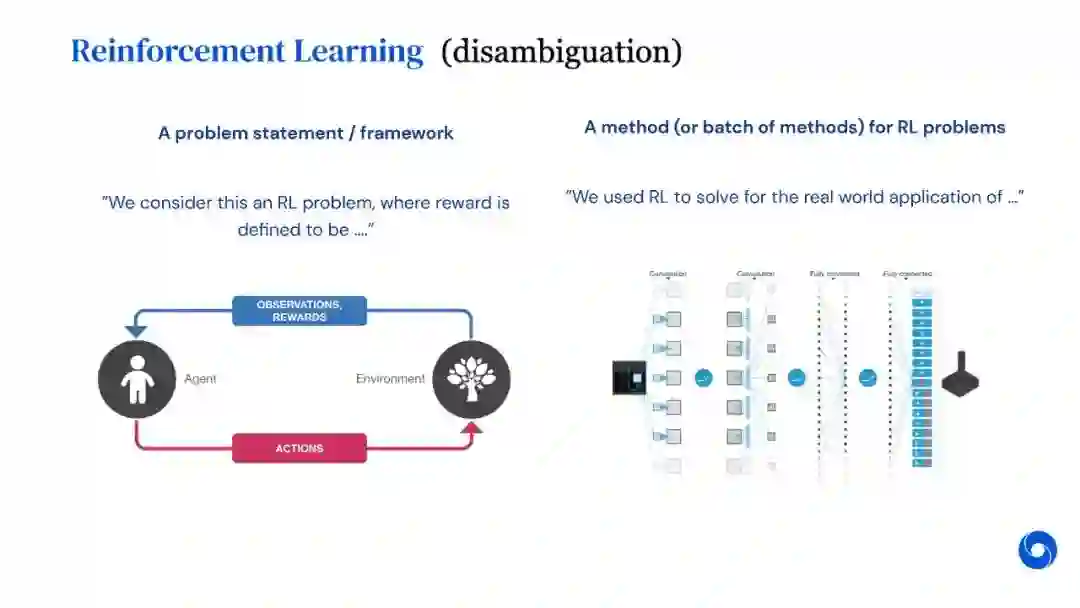
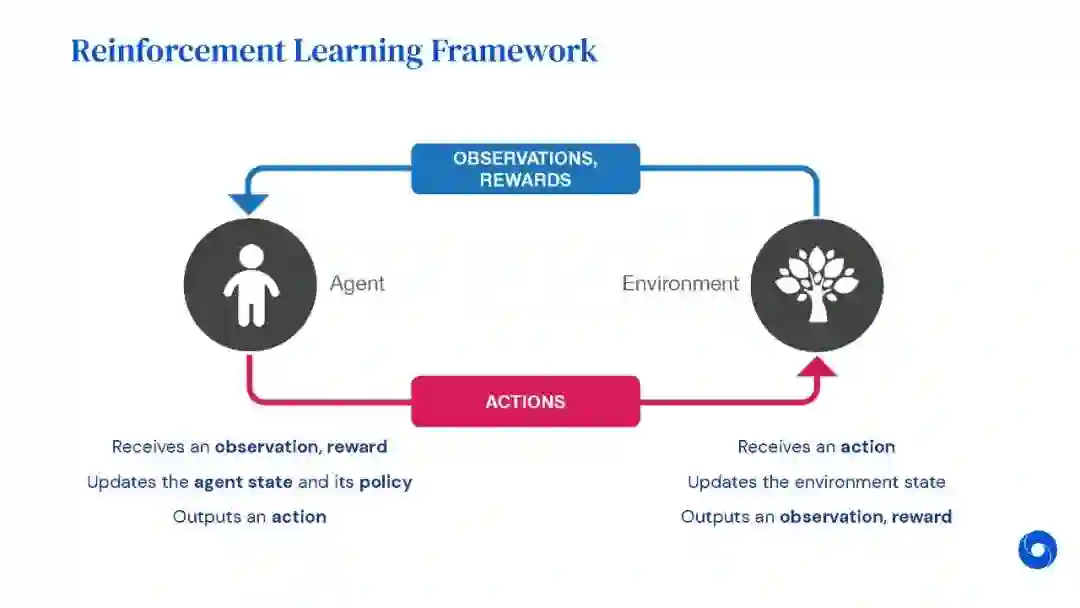
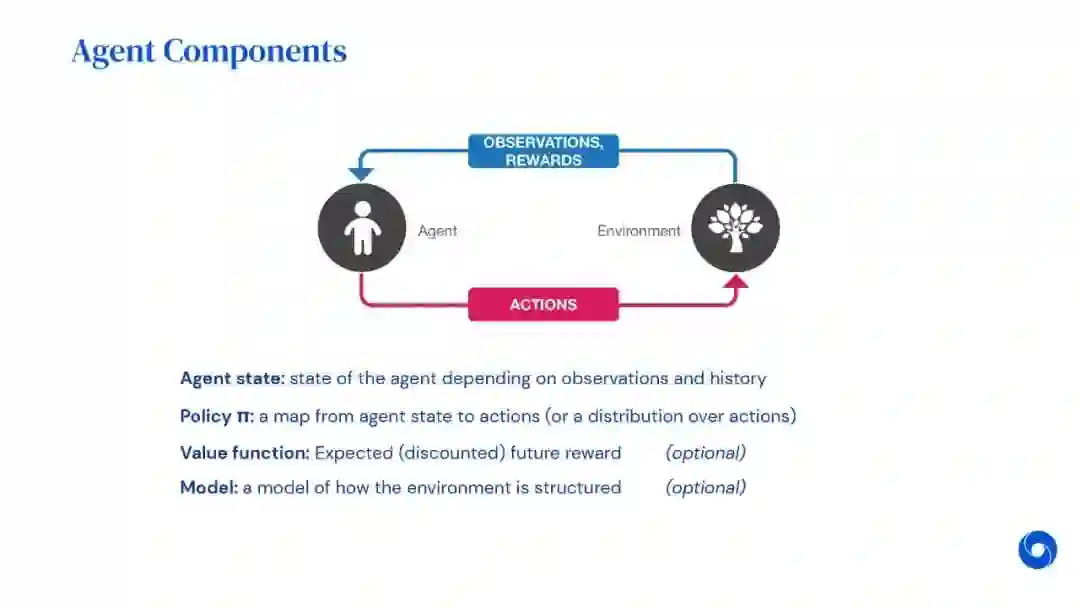
强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。
专知会员服务
35+阅读 · 2019年11月2日

相关VIP内容
专知会员服务
35+阅读 · 2019年11月2日
相关资讯