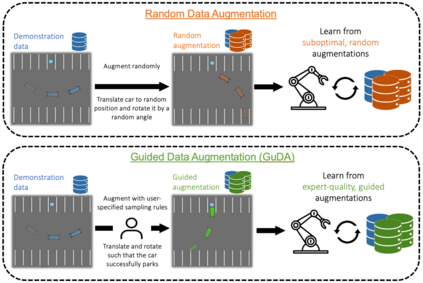
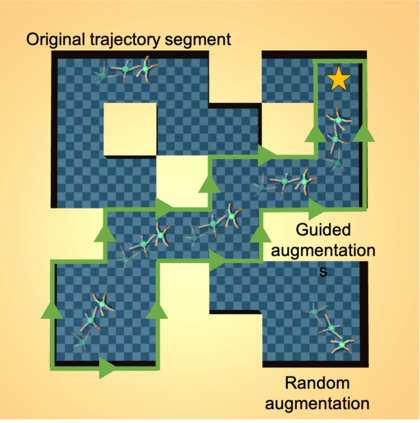
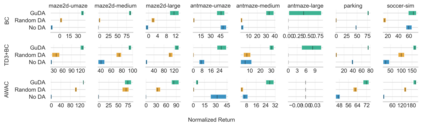
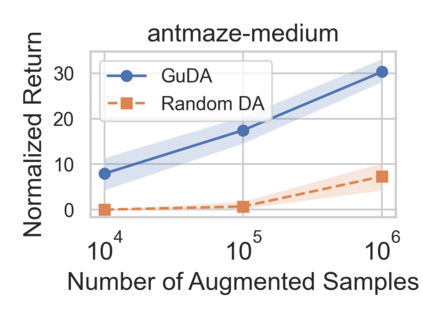
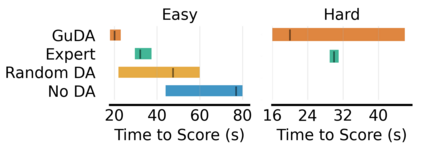
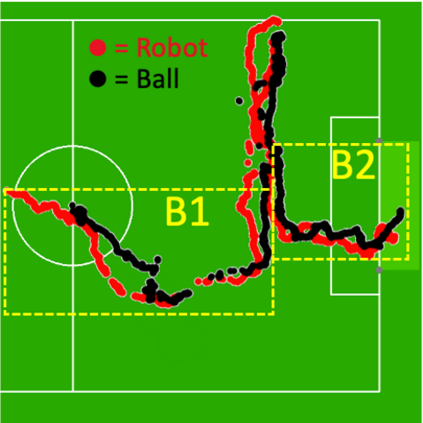
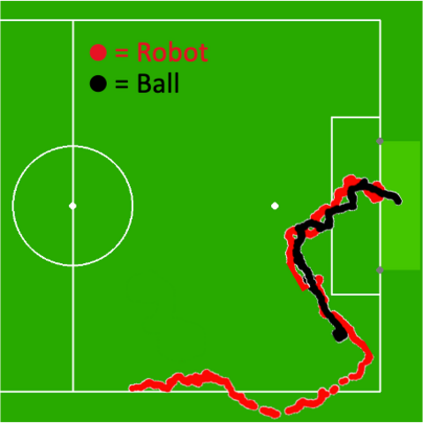
Learning from demonstration (LfD) is a popular technique that uses expert demonstrations to learn robot control policies. However, the difficulty in acquiring expert-quality demonstrations limits the applicability of LfD methods: real-world data collection is often costly, and the quality of the demonstrations depends greatly on the demonstrator's abilities and safety concerns. A number of works have leveraged data augmentation (DA) to inexpensively generate additional demonstration data, but most DA works generate augmented data in a random fashion and ultimately produce highly suboptimal data. In this work, we propose Guided Data Augmentation (GuDA), a human-guided DA framework that generates expert-quality augmented data. The key insight of GuDA is that while it may be difficult to demonstrate the sequence of actions required to produce expert data, a user can often easily identify when an augmented trajectory segment represents task progress. Thus, the user can impose a series of simple rules on the DA process to automatically generate augmented samples that approximate expert behavior. To extract a policy from GuDA, we use off-the-shelf offline reinforcement learning and behavior cloning algorithms. We evaluate GuDA on a physical robot soccer task as well as simulated D4RL navigation tasks, a simulated autonomous driving task, and a simulated soccer task. Empirically, we find that GuDA enables learning from a small set of potentially suboptimal demonstrations and substantially outperforms a DA strategy that samples augmented data randomly.
翻译:暂无翻译