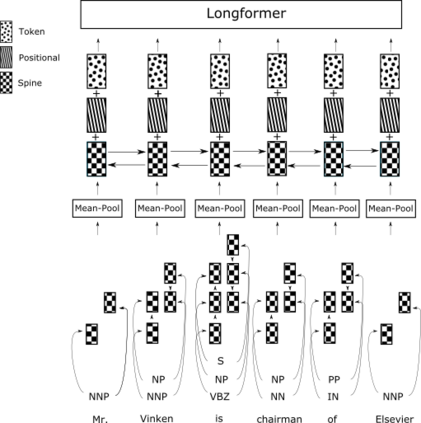
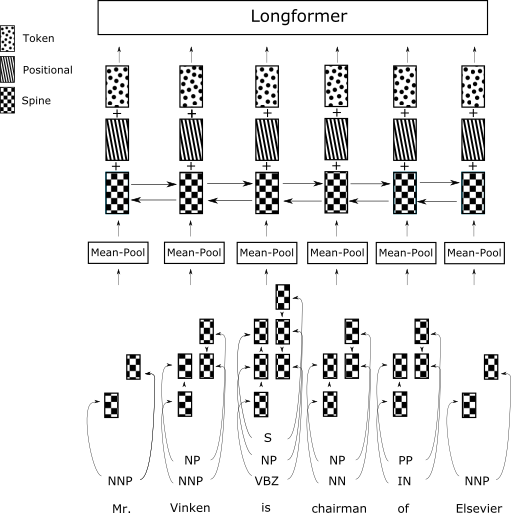
Summarizing novel chapters is a difficult task due to the input length and the fact that sentences that appear in the desired summaries draw content from multiple places throughout the chapter. We present a pipelined extractive-abstractive approach where the extractive step filters the content that is passed to the abstractive component. Extremely lengthy input also results in a highly skewed dataset towards negative instances for extractive summarization; we thus adopt a margin ranking loss for extraction to encourage separation between positive and negative examples. Our extraction component operates at the constituent level; our approach to this problem enriches the text with spinal tree information which provides syntactic context (in the form of constituents) to the extraction model. We show an improvement of 3.71 Rouge-1 points over best results reported in prior work on an existing novel chapter dataset.
翻译:总结新章节是一项艰巨的任务,因为投入篇幅长,而且预期摘要中出现的句子内容来自该章的多个地方。我们提出了一个管道式的采掘-吸收方法,即采掘步骤过滤传递到抽象部分的内容。极其冗长的投入还导致高度偏斜的数据集,形成采掘总结的负面实例;因此,我们采用了抽取的差值损失排序,以鼓励将正和负实例分开。我们的抽取部分在构件层面运作;我们处理这一问题的方法丰富了案文,增加了脊椎树信息,为提取模型提供了综合背景(以成分形式),我们显示比以前关于现有新章节数据集的工作报告的最佳结果改进了3.71个红色-1点。