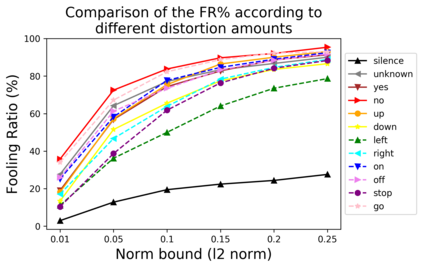
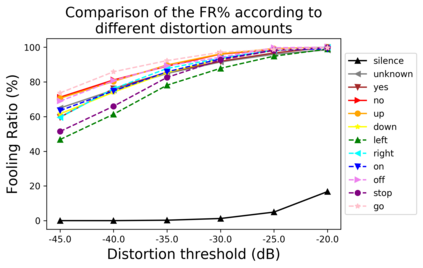
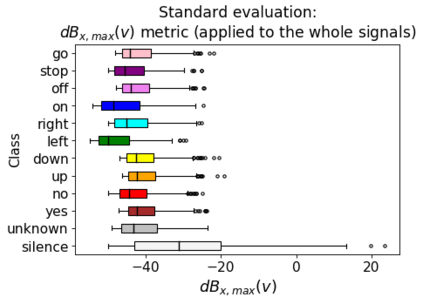
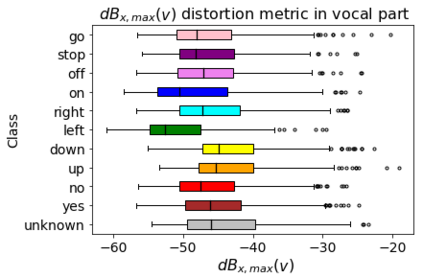
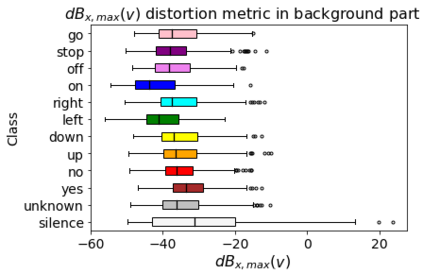
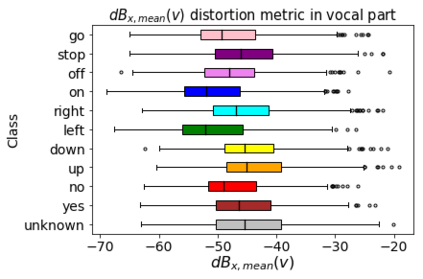
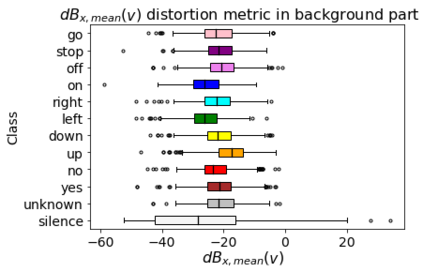
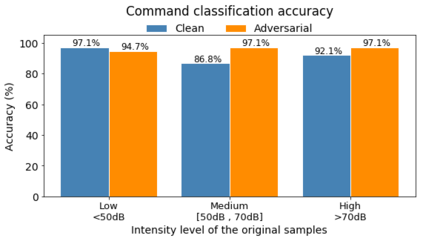
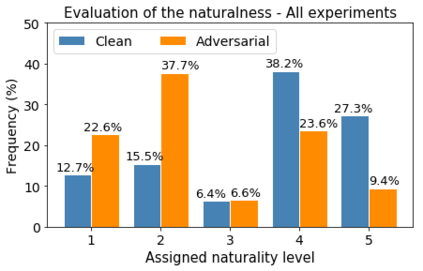
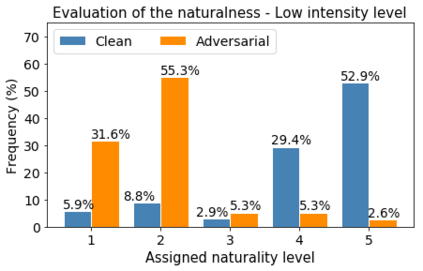
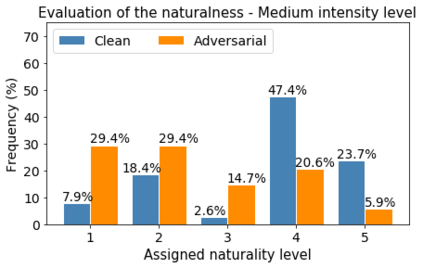
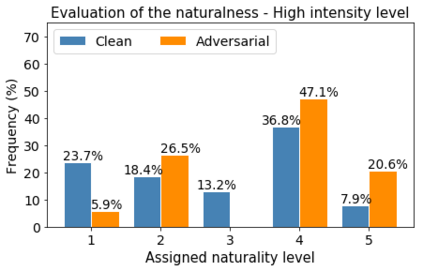
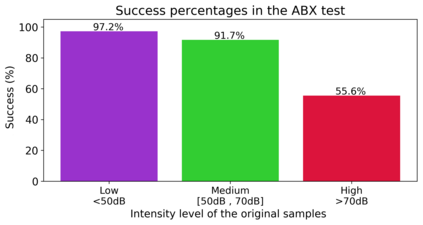
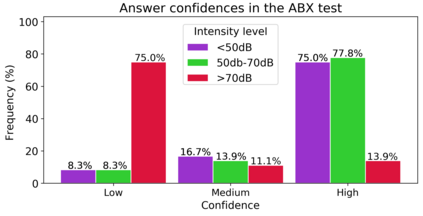
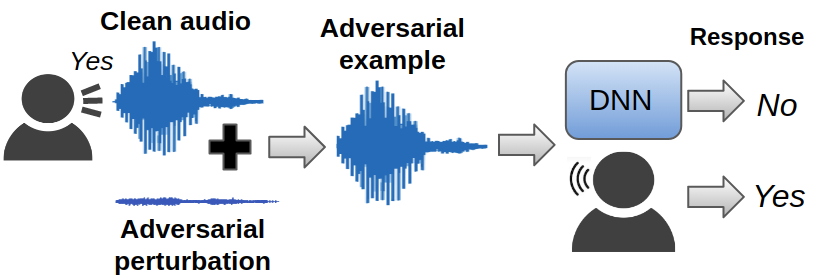
Human-machine interaction is increasingly dependent on speech communication. Machine Learning models are usually applied to interpret human speech commands. However, these models can be fooled by adversarial examples, which are inputs intentionally perturbed to produce a wrong prediction without being noticed. While much research has been focused on developing new techniques to generate adversarial perturbations, less attention has been given to aspects that determine whether and how the perturbations are noticed by humans. This question is relevant since high fooling rates of proposed adversarial perturbation strategies are only valuable if the perturbations are not detectable. In this paper we investigate to which extent the distortion metrics proposed in the literature for audio adversarial examples, and which are commonly applied to evaluate the effectiveness of methods for generating these attacks, are a reliable measure of the human perception of the perturbations. Using an analytical framework, and an experiment in which 18 subjects evaluate audio adversarial examples, we demonstrate that the metrics employed by convention are not a reliable measure of the perceptual similarity of adversarial examples in the audio domain.
翻译:人类机器互动越来越依赖于语言交流。机器学习模型通常用于解释人类语言指令。然而,这些模型可能被对抗性例子所愚弄,这些例子被故意干扰以产生错误的预测而不受注意。虽然许多研究侧重于开发新技术以产生对抗性扰动,但较少注意确定人类是否以及如何注意到扰动的方面。这个问题具有相关性,因为拟议的对抗性扰动战略的高愚弄率只有在扰动无法被察觉的情况下才具有价值。在本文件中,我们调查了文献中为声音对抗性例子建议的扭曲度量度,通常用于评价产生这些攻击的方法的有效性,这是人类对干扰感知的可靠衡量尺度。我们利用分析框架和18个主体评价声斗实例的实验,证明公约使用的指标不是音响领域对抗性实例概念相似性的可靠衡量尺度。