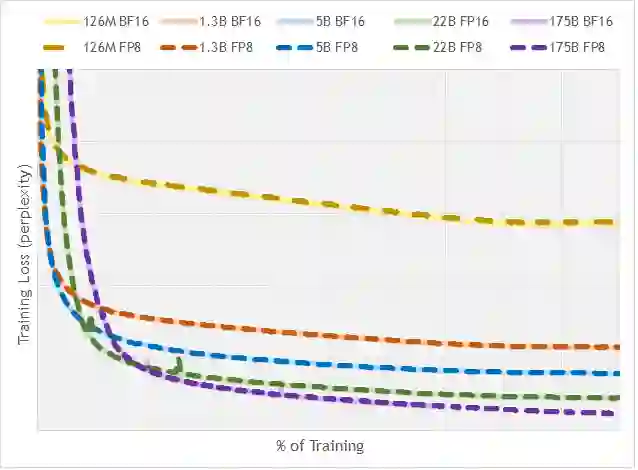
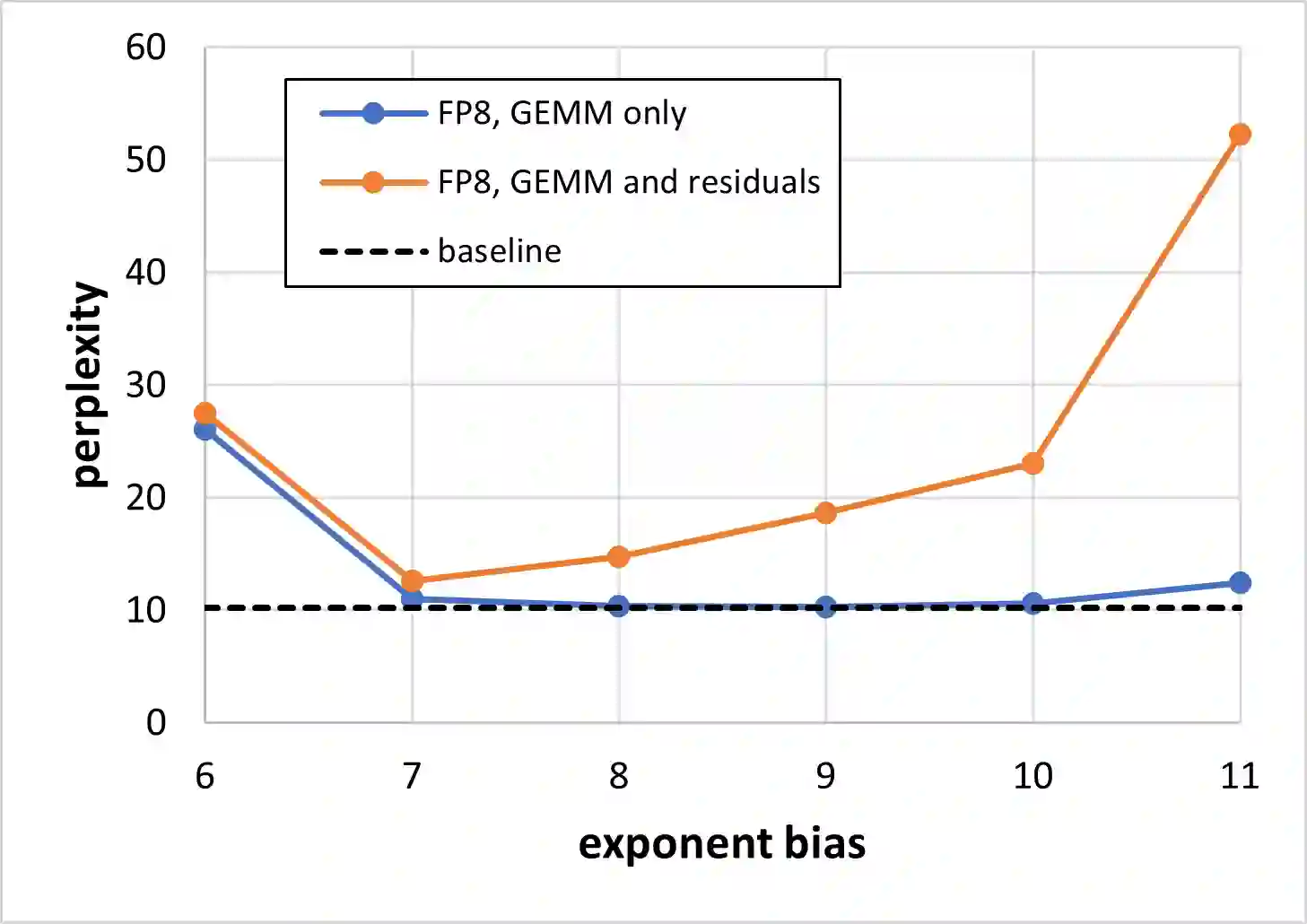
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
翻译:FP8是加速深层次培训的自然进步,超越了现代处理器中常见的16位模式的16位模式。在本文中,我们建议采用8位浮动点(FP8)二进制交换格式,由两种编码组成:E4M3(4位指数和3位曼特萨)和E5M2(5位指数和2位曼特萨)和E5M2(5位指数和2位曼特萨)。E5M2遵循IEEE 754特殊价值代表协议,而E4M3的动态范围则通过不代表无限和只有一位纳恩斯曼蒂萨位模式而扩大。我们展示了FP8格式在各种图像和语言任务方面的功效,与16位培训课程取得的结果质量相匹配。我们的研究涵盖主要的现代神经网络结构(CNN、RNNIS和2位曼特和2位曼特基模型),使所有超参数与16位基线培训课程保持一致。我们的培训实验包括大型、最高至175B参数、语言模型。我们还在16位固定语言模式中检查了FP8点后培训18位模式。