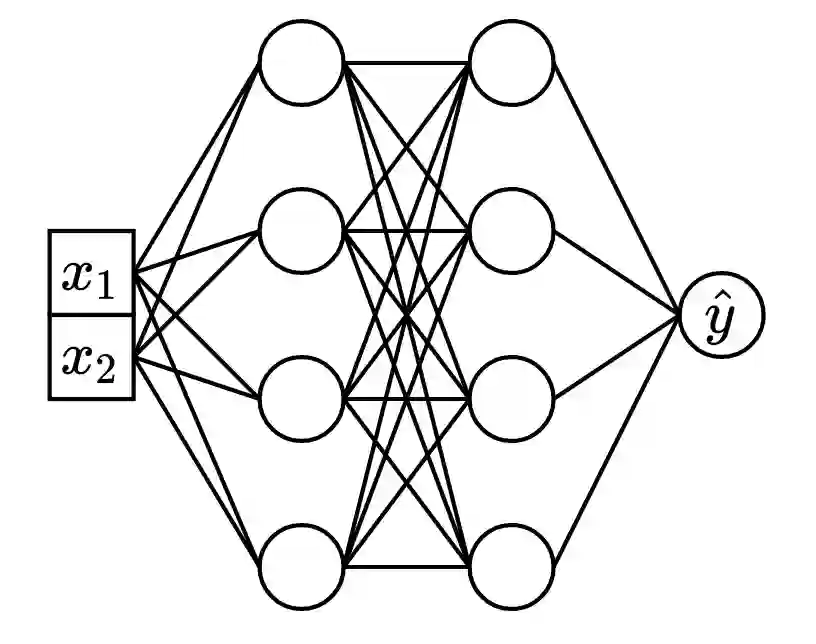
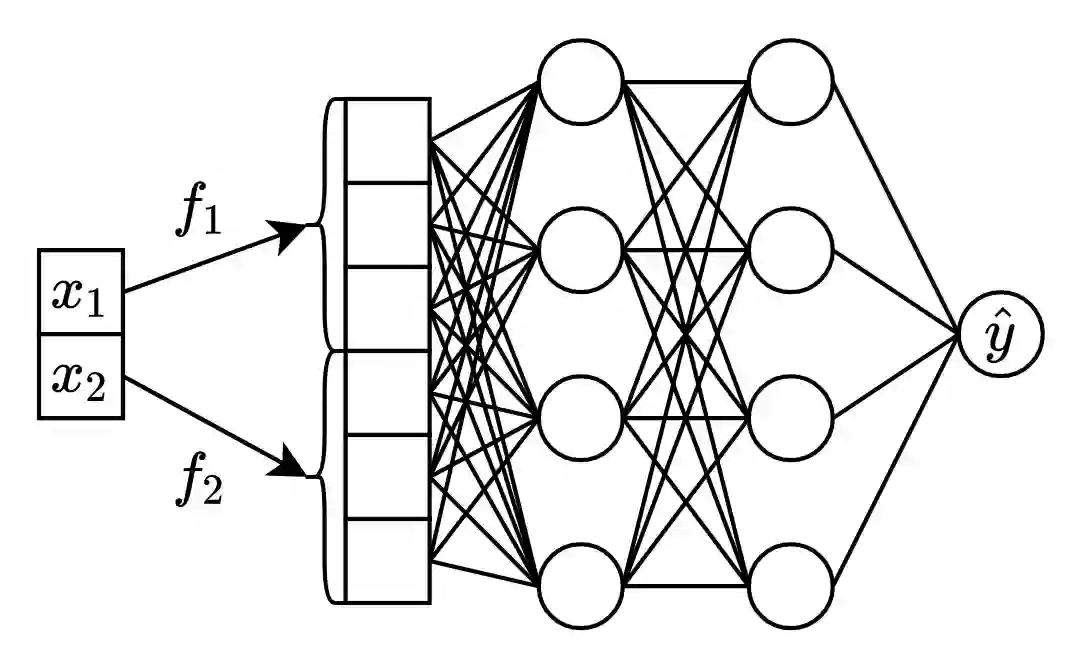
Deep learning (DL) models for tabular data problems (e.g. classification, regression) are currently receiving increasingly more attention from researchers. However, despite the recent efforts, the non-DL algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution for these problems. One of the research directions aimed at improving the position of tabular DL involves designing so-called retrieval-augmented models. For a target object, such models retrieve other objects (e.g. the nearest neighbors) from the available training data and use their features and labels to make a better prediction. In this work, we present TabR -- essentially, a feed-forward network with a custom k-Nearest-Neighbors-like component in the middle. On a set of public benchmarks with datasets up to several million objects, TabR marks a big step forward for tabular DL: it demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed "GBDT-friendly" benchmark (see Figure 1). Among the important findings and technical details powering TabR, the main ones lie in the attention-like mechanism that is responsible for retrieving the nearest neighbors and extracting valuable signal from them. In addition to the much higher performance, TabR is simple and significantly more efficient compared to prior retrieval-based tabular DL models.
翻译:暂无翻译