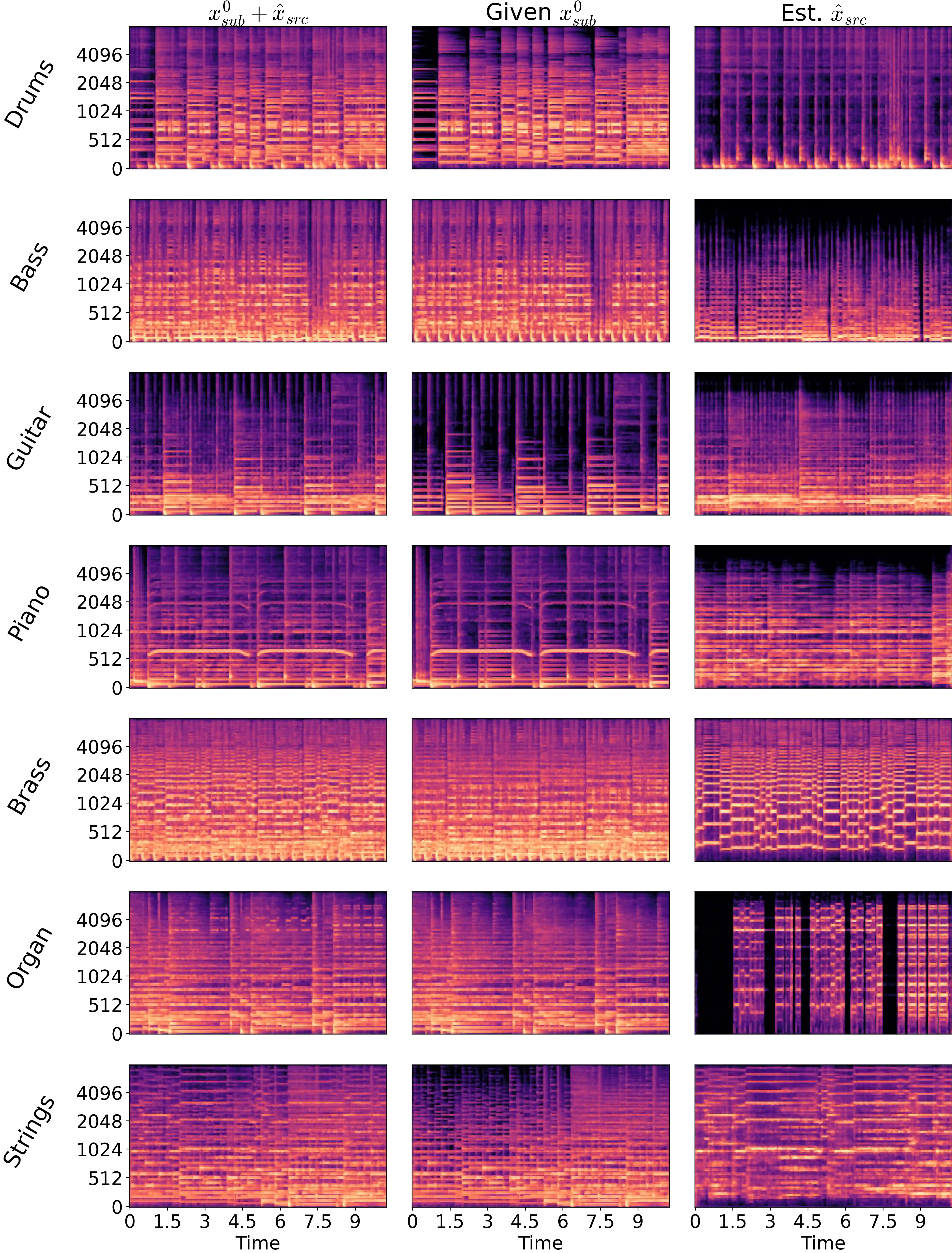
We present MGE-LDM, a unified latent diffusion framework for simultaneous music generation, source imputation, and query-driven source separation. Unlike prior approaches constrained to fixed instrument classes, MGE-LDM learns a joint distribution over full mixtures, submixtures, and individual stems within a single compact latent diffusion model. At inference, MGE-LDM enables (1) complete mixture generation, (2) partial generation (i.e., source imputation), and (3) text-conditioned extraction of arbitrary sources. By formulating both separation and imputation as conditional inpainting tasks in the latent space, our approach supports flexible, class-agnostic manipulation of arbitrary instrument sources. Notably, MGE-LDM can be trained jointly across heterogeneous multi-track datasets (e.g., Slakh2100, MUSDB18, MoisesDB) without relying on predefined instrument categories. Audio samples are available at our project page: https://yoongi43.github.io/MGELDM_Samples/.
翻译:我们提出了MGE-LDM,一个用于同时进行音乐生成、源填补和查询驱动源分离的统一潜在扩散框架。与先前受限于固定乐器类别的方法不同,MGE-LDM在一个紧凑的单一潜在扩散模型中学习完整混音、子混音及独立音轨的联合分布。在推理阶段,MGE-LDM能够实现:(1)完整混音生成,(2)部分生成(即源填补),以及(3)基于文本条件的任意源提取。通过将分离和填补任务均构建为潜在空间中的条件修复问题,我们的方法支持对任意乐器源进行灵活且与类别无关的操控。值得注意的是,MGE-LDM可以在异构多轨数据集(例如Slakh2100、MUSDB18、MoisesDB)上进行联合训练,而无需依赖预定义的乐器类别。音频样本可在我们的项目页面获取:https://yoongi43.github.io/MGELDM_Samples/。