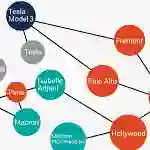
In the ever-evolving landscape of natural language processing and information retrieval, the need for robust and domain-specific entity linking algorithms has become increasingly apparent. It is crucial in a considerable number of fields such as humanities, technical writing and biomedical sciences to enrich texts with semantics and discover more knowledge. The use of Named Entity Disambiguation (NED) in such domains requires handling noisy texts, low resource settings and domain-specific KBs. Existing approaches are mostly inappropriate for such scenarios, as they either depend on training data or are not flexible enough to work with domain-specific KBs. Thus in this work, we present an unsupervised approach leveraging the concept of Group Steiner Trees (GST), which can identify the most relevant candidates for entity disambiguation using the contextual similarities across candidate entities for all the mentions present in a document. We outperform the state-of-the-art unsupervised methods by more than 40\% (in avg.) in terms of Precision@1 across various domain-specific datasets.
翻译:暂无翻译