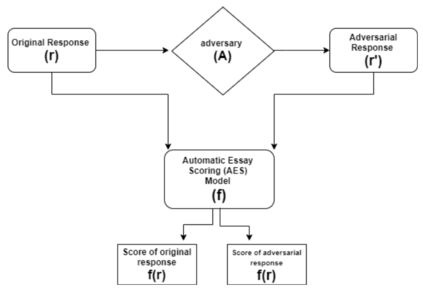
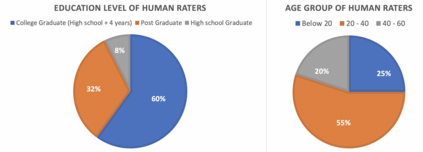
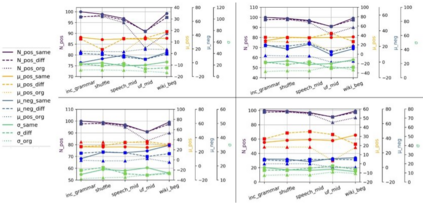
Automatic scoring engines have been used for scoring approximately fifteen million test-takers in just the last three years. This number is increasing further due to COVID-19 and the associated automation of education and testing. Despite such wide usage, the AI-based testing literature of these "intelligent" models is highly lacking. Most of the papers proposing new models rely only on quadratic weighted kappa (QWK) based agreement with human raters for showing model efficacy. However, this effectively ignores the highly multi-feature nature of essay scoring. Essay scoring depends on features like coherence, grammar, relevance, sufficiency and, vocabulary. To date, there has been no study testing Automated Essay Scoring: AES systems holistically on all these features. With this motivation, we propose a model agnostic adversarial evaluation scheme and associated metrics for AES systems to test their natural language understanding capabilities and overall robustness. We evaluate the current state-of-the-art AES models using the proposed scheme and report the results on five recent models. These models range from feature-engineering-based approaches to the latest deep learning algorithms. We find that AES models are highly overstable. Even heavy modifications(as much as 25%) with content unrelated to the topic of the questions do not decrease the score produced by the models. On the other hand, irrelevant content, on average, increases the scores, thus showing that the model evaluation strategy and rubrics should be reconsidered. We also ask 200 human raters to score both an original and adversarial response to seeing if humans can detect differences between the two and whether they agree with the scores assigned by auto scores.
翻译:仅在过去三年里,就使用了自动评分引擎来评分大约1500万个考取者。由于COVID-19和相关的教育和测试自动化,这个数字正在进一步增加。尽管使用范围如此广泛,但是这些“智能”模型的AI测试文献非常缺乏。大多数提议新模型的论文只依靠基于四角加权卡帕(QWK)的人类考评员协议来显示模型的功效。然而,这实际上忽略了作文评分的高度多性能。 批量评分取决于一致性、 语法、 相关性、 充足性和词汇等特征。 截止到今天,还没有研究测试自动的Essay Scoring: AES系统在所有这些特征上的整体性都非常缺乏。有了这种动机,我们建议了AES系统模型的模量性对抗机制和相关衡量标准,以测试其自然语言理解能力和总体稳健性。我们用拟议的方法评估当前最先进的AES模型, 并报告最近5个模型的响应情况。这些模型从基于地定位的计算方法到基于配置方法的计算方法的计算方法, 以及最新的不甚低的数学评分数率, 。我们发现, 也是高分数的评分的模型, 。我们通过高分数的评分数 。我们发现, 。