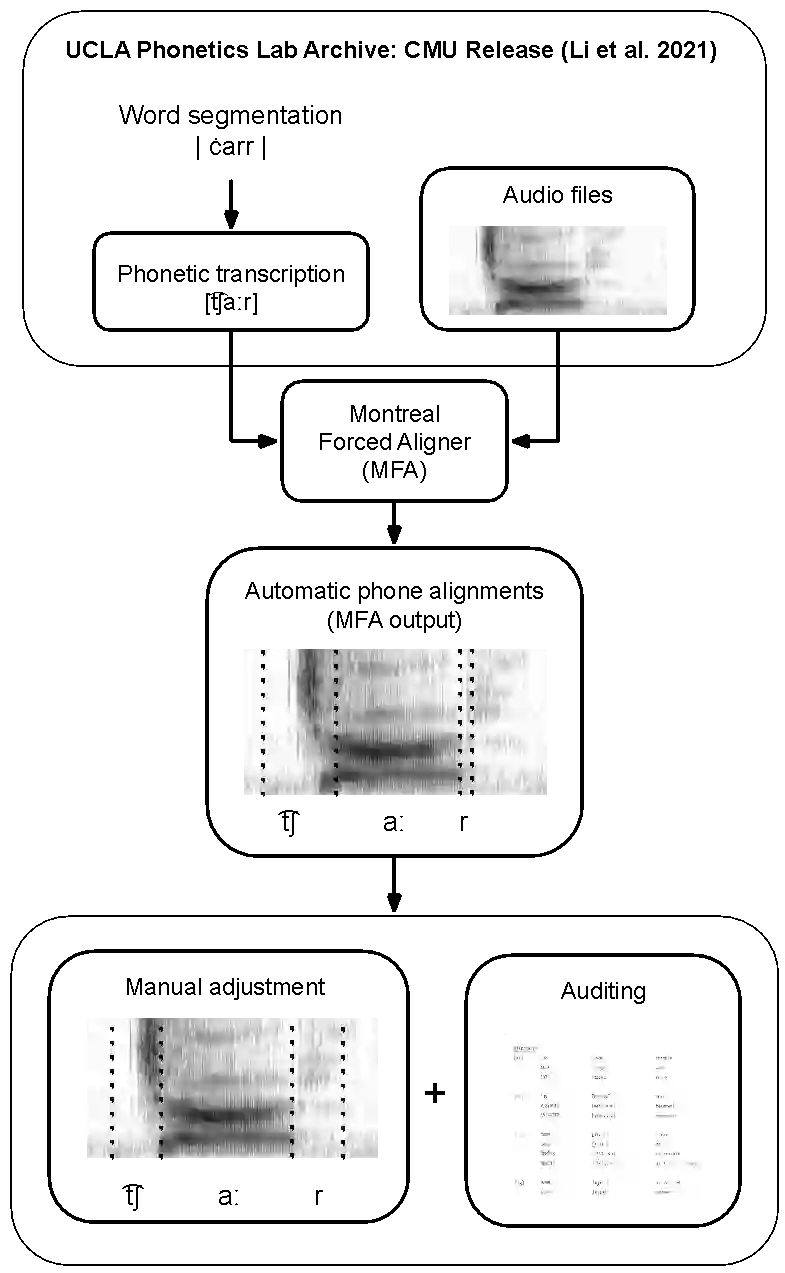
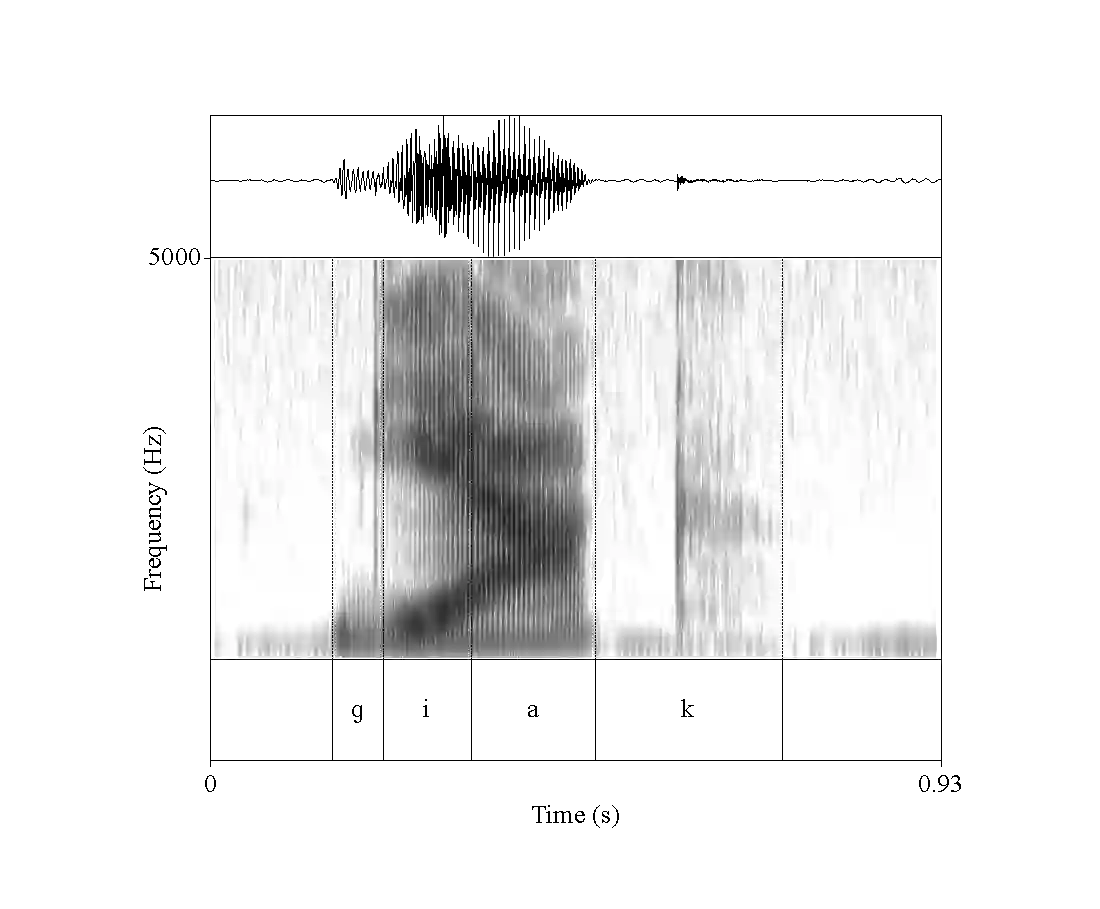
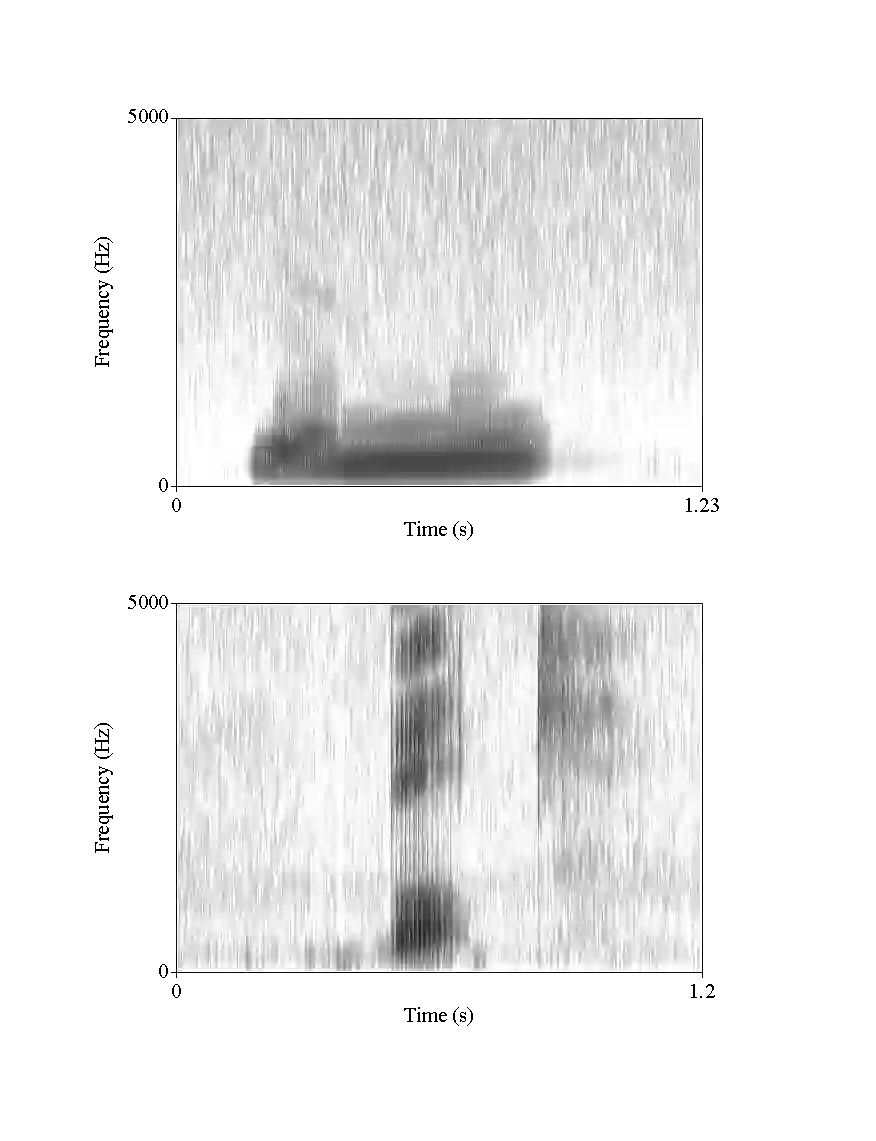
Research in speech technologies and comparative linguistics depends on access to diverse and accessible speech data. The UCLA Phonetics Lab Archive is one of the earliest multilingual speech corpora, with long-form audio recordings and phonetic transcriptions for 314 languages (Ladefoged et al., 2009). Recently, 95 of these languages were time-aligned with word-level phonetic transcriptions (Li et al., 2021). Here we present VoxAngeles, a corpus of audited phonetic transcriptions and phone-level alignments of the UCLA Phonetics Lab Archive, which uses the 95-language CMU re-release as our starting point. VoxAngeles also includes word- and phone-level segmentations from the original UCLA corpus, as well as phonetic measurements of word and phone durations, vowel formants, and vowel f0. This corpus enhances the usability of the original data, particularly for quantitative phonetic typology, as demonstrated through a case study of vowel intrinsic f0. We also discuss the utility of the VoxAngeles corpus for general research and pedagogy in crosslinguistic phonetics, as well as for low-resource and multilingual speech technologies. VoxAngeles is free to download and use under a CC-BY-NC 4.0 license.
翻译:暂无翻译