
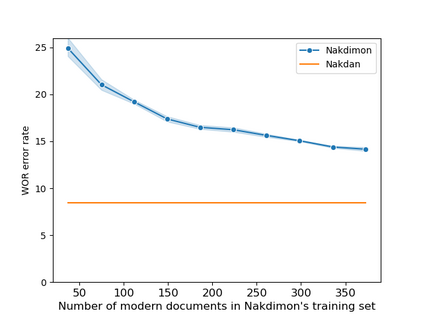
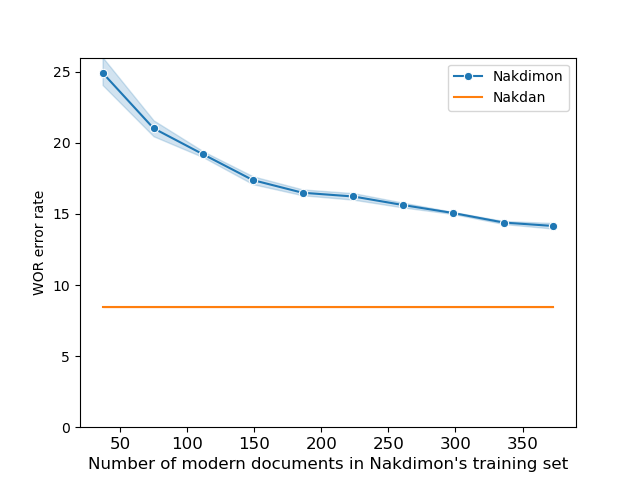
We demonstrate that it is feasible to diacritize Hebrew script without any human-curated resources other than plain diacritized text. We present NAKDIMON, a two-layer character level LSTM, that performs on par with much more complicated curation-dependent systems, across a diverse array of modern Hebrew sources.
翻译:我们证明,在除纯正正正正正正正正正正正正正正文字之外没有任何人力精良资源的情况下,对希伯来文字进行误判是可行的。 我们展示了NAKDIMON,一个两级字符级的LSTM,它与复杂得多的法理系统一样,在现代希伯来各种现代希伯来来源中运行。
相关内容
Arxiv
0+阅读 · 2022年6月20日
Arxiv
0+阅读 · 2022年6月17日


相关VIP内容
相关资讯