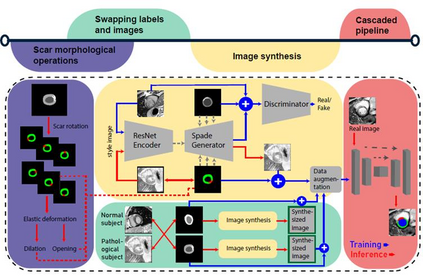
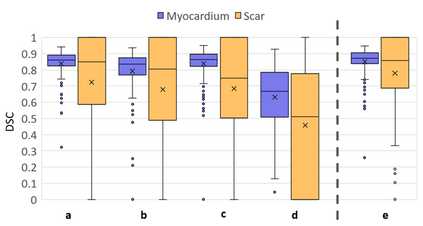
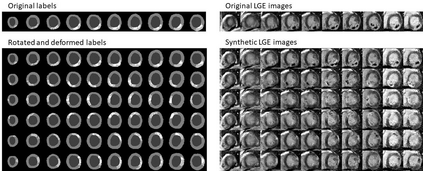
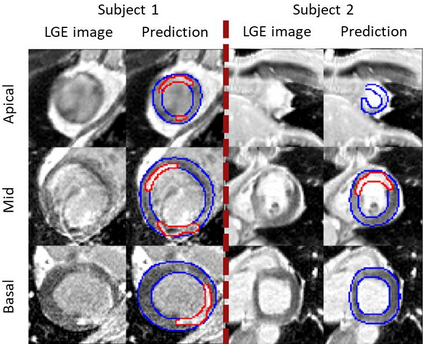
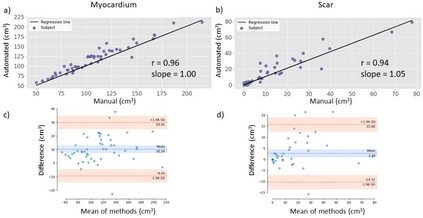
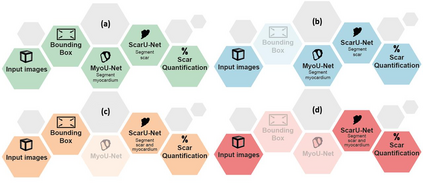
Background: The clinical utility of late gadolinium enhancement (LGE) cardiac MRI is limited by the lack of standardization, and time-consuming postprocessing. In this work, we tested the hypothesis that a cascaded deep learning pipeline trained with augmentation by synthetically generated data would improve model accuracy and robustness for automated scar quantification. Methods: A cascaded pipeline consisting of three consecutive neural networks is proposed, starting with a bounding box regression network to identify a region of interest around the left ventricular (LV) myocardium. Two further nnU-Net models are then used to segment the myocardium and, if present, scar. The models were trained on the data from the EMIDEC challenge, supplemented with an extensive synthetic dataset generated with a conditional GAN. Results: The cascaded pipeline significantly outperformed a single nnU-Net directly segmenting both the myocardium (mean Dice similarity coefficient (DSC) (standard deviation (SD)): 0.84 (0.09) vs 0.63 (0.20), p < 0.01) and scar (DSC: 0.72 (0.34) vs 0.46 (0.39), p < 0.01) on a per-slice level. The inclusion of the synthetic data as data augmentation during training improved the scar segmentation DSC by 0.06 (p < 0.01). The mean DSC per-subject on the challenge test set, for the cascaded pipeline augmented by synthetic generated data, was 0.86 (0.03) and 0.67 (0.29) for myocardium and scar, respectively. Conclusion: A cascaded deep learning-based pipeline trained with augmentation by synthetically generated data leads to myocardium and scar segmentations that are similar to the manual operator, and outperforms direct segmentation without the synthetic images.
翻译:在这项工作中,我们测试了以下假设:经过合成数据增强培训的深层学习管道,如果通过合成数据增强,将提高模型的准确性和稳健性,以进行自动伤疤量化。 方法:建议采用由连续三个神经网络组成的累进管道,从一个捆绑盒回归网络开始,以确定左心血管(LV)心肌内核内核周围感兴趣的区域。然后,再使用另外两个直流螺旋内核内核-网络模型,以分割心肌和(如果存在的话)疤痕。这些模型经过了EMIDEC挑战数据的培训,并辅之以以有条件GAN生成的广泛合成数据集。结果:累进式输气管道大大超过单一的NNU-网络,直接分割心肌内核(表示DSC相似系数(标准偏差(SD) 0.84 (0.09) vs 0.63, p < 0.01) 和伤疤(DC: 0.72 (0.34) 输血压-直径直径) 和血浆(经培训的0.46) 数据,通过O.06/0.06; 我的SIC-递化数据(通过升级) 数据,通过升级数据测试,通过升级数据(通过升级) 数据(通过升级) 升级数据,通过每的升级数据(通过升级)的升级) 升级数据(通过升级) 升级) 和升级数据(通过升级数据(通过升级)的升级数据(通过升级)的升级)的升级),通过数据(通过升级)的升级数据(通过升级数据(通过升级)和升级)。