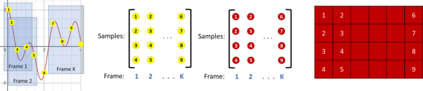
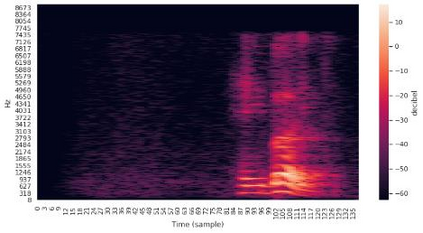
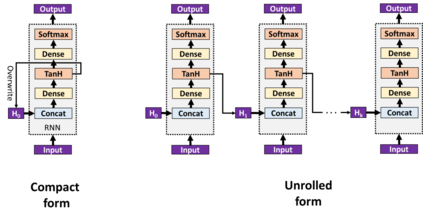
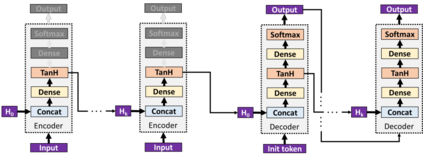
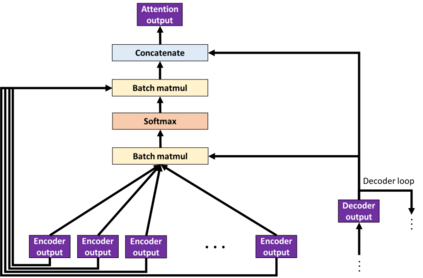
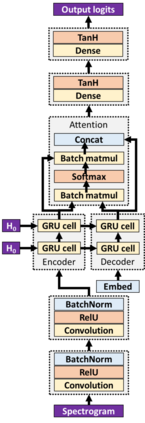
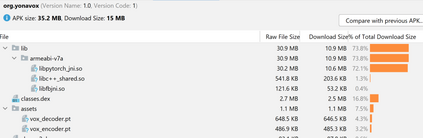
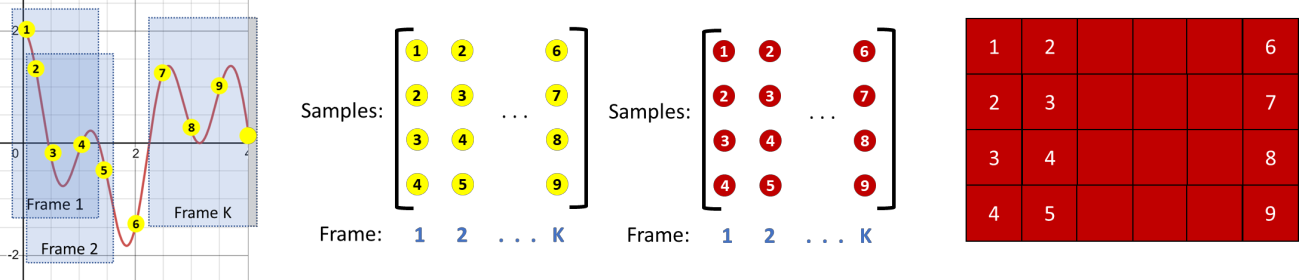
While speech recognition has seen a surge in interest and research over the last decade, most machine learning models for speech recognition either require large training datasets or lots of storage and memory. Combined with the prominence of English as the number one language in which audio data is available, this means most other languages currently lack good speech recognition models. The method presented in this paper shows how to create and train models for speech recognition in any language which are not only highly accurate, but also require very little storage, memory and training data when compared with traditional models. This allows training models to recognize any language and deploying them on edge devices such as mobile phones or car displays for fast real-time speech recognition.
翻译:虽然在过去十年中,语音识别和研究出现了兴趣和研究的激增,但大多数语音识别的机器学习模式要么需要大量的培训数据集,要么需要大量的存储和记忆。加上英语作为提供音频数据的头号语言的突出地位,这意味着大多数其他语言目前缺乏良好的语音识别模式。本文介绍的方法表明如何创建和培训语音识别模式,这些语言不仅非常准确,而且与传统模式相比也很少需要存储、记忆和培训数据。这使得培训模式能够识别任何语言,并将其部署在诸如移动电话或汽车显示器等边端设备上,以便快速实时语音识别。