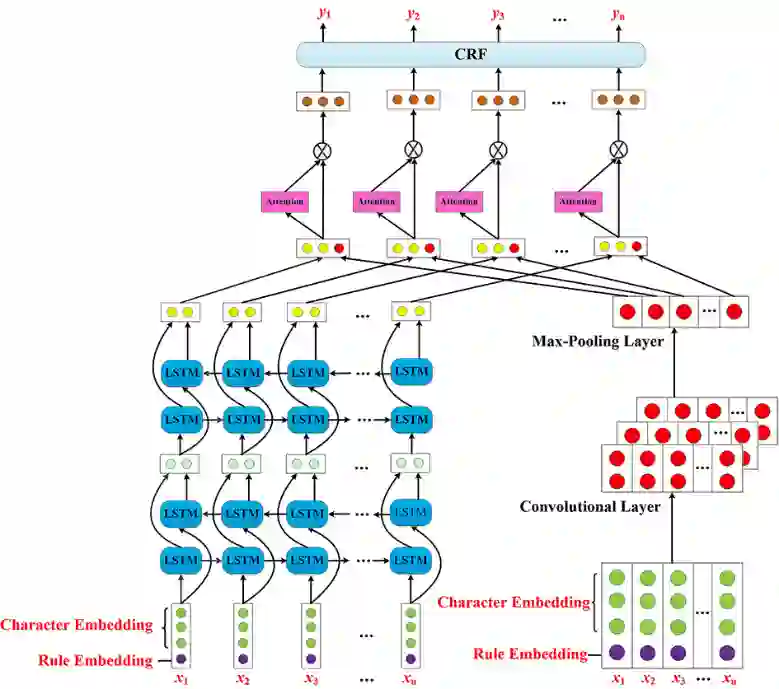
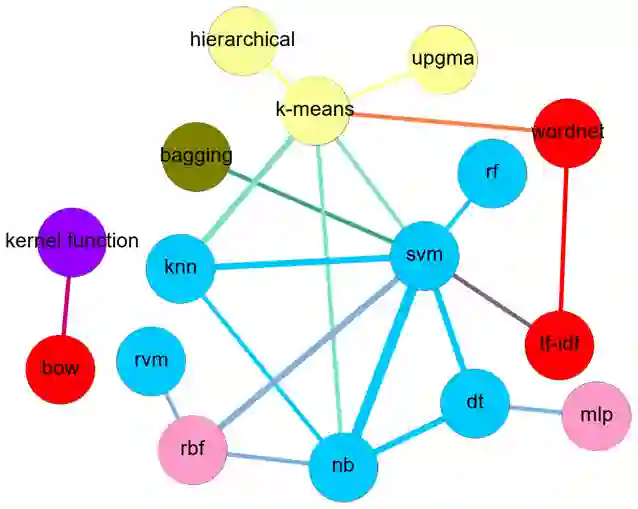
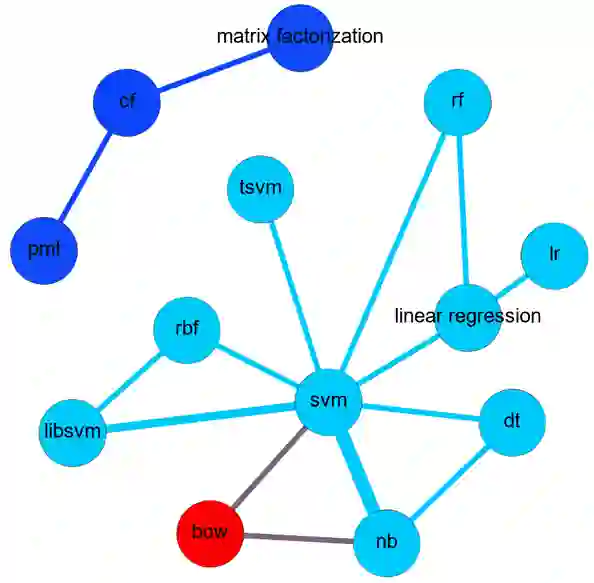
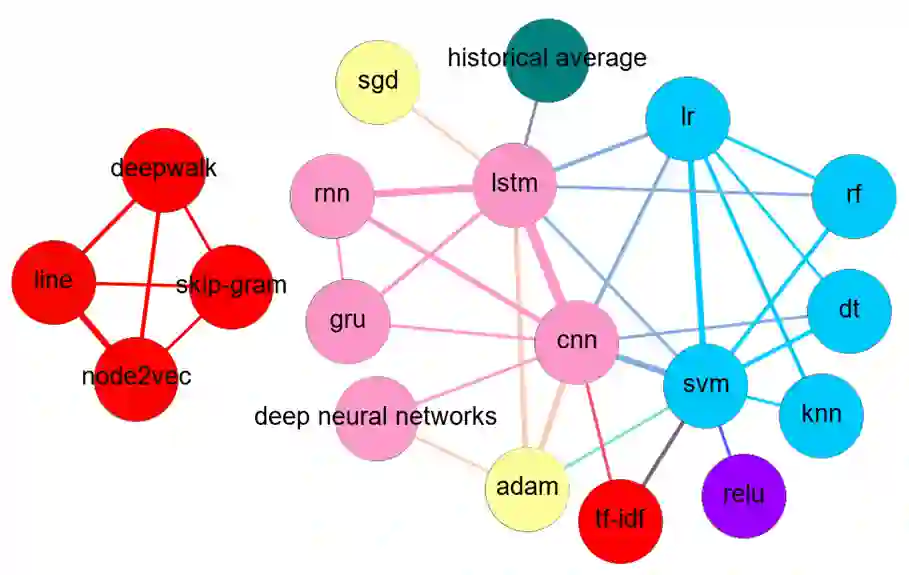
Literature analysis facilitates researchers better understanding the development of science and technology. The conventional literature analysis focuses on the topics, authors, abstracts, keywords, references, etc., and rarely pays attention to the content of papers. In the field of machine learning, the involved methods (M) and datasets (D) are key information in papers. The extraction and mining of M and D are useful for discipline analysis and algorithm recommendation. In this paper, we propose a novel entity recognition model, called MDER, and constructe datasets from the papers of the PAKDD conferences (2009-2019). Some preliminary experiments are conducted to assess the extraction performance and the mining results are visualized.
翻译:传统文献分析侧重于专题、作者、摘要、关键词、参考文献等,很少关注论文的内容。在机器学习领域,所涉方法(M)和数据集(D)是论文中的关键信息。M和D的提取和开采有助于学科分析和算法建议。本文提出一个新的实体识别模型,称为MDER,并构建PAKDD会议(2009-2019年)文件中的数据集。进行了一些初步实验,以评估开采绩效,并直观地展示采矿结果。