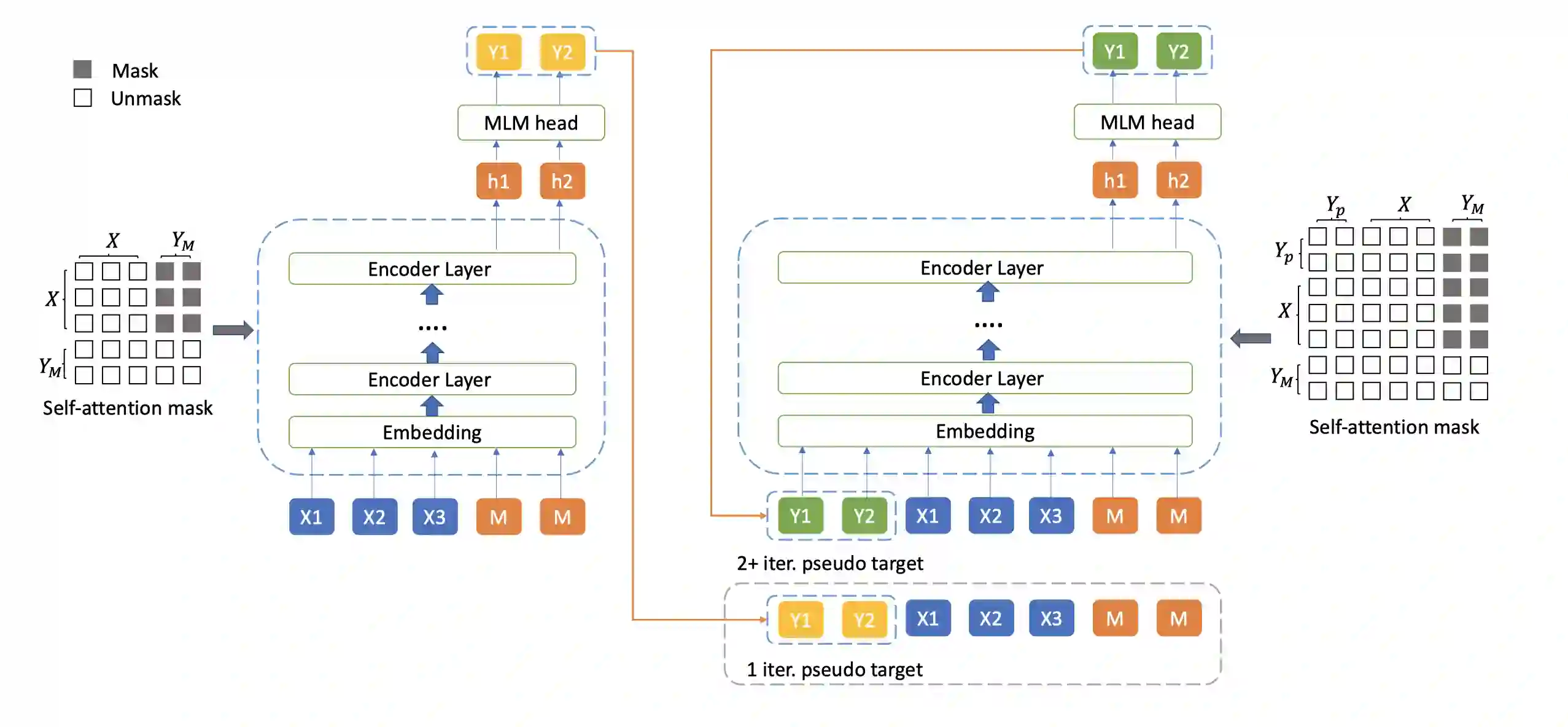
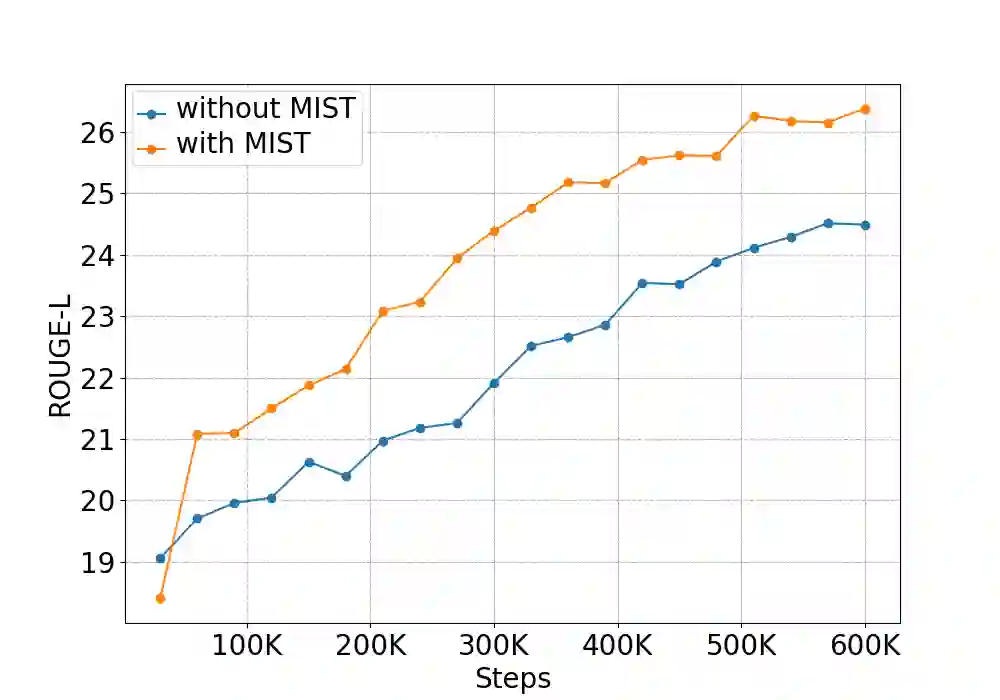
While pre-trained language models have achieved great success on various natural language understanding tasks, how to effectively leverage them into non-autoregressive generation tasks remains a challenge. To solve this problem, we present a non-autoregressive generation model based on pre-trained transformer models. To bridge the gap between autoregressive and non-autoregressive models, we propose a simple and effective iterative training method called MIx Source and pseudo Target (MIST). Unlike other iterative decoding methods, which sacrifice the inference speed to achieve better performance based on multiple decoding iterations, MIST works in the training stage and has no effect on inference time. Our experiments on three generation benchmarks including question generation, summarization and paraphrase generation, show that the proposed framework achieves the new state-of-the-art results for fully non-autoregressive models. We also demonstrate that our method can be used to a variety of pre-trained models. For instance, MIST based on the small pre-trained model also obtains comparable performance with seq2seq models.
翻译:虽然经过培训的语文模式在各种自然语言理解任务方面取得了巨大成功,但如何有效地将这些模式用于非偏移的一代任务仍是一项挑战。为了解决这一问题,我们展示了一种基于预先培训的变压器模型的非偏移一代模式。为了缩小自动递减和非非偏移模型之间的差距,我们提出了一种简单而有效的迭代培训方法,称为MIx源代码和假目标(MIST ) 。与其他迭代解码方法不同,这些方法牺牲了根据多重解码迭代法实现更好业绩的推断速度,而MIST在培训阶段工作,对推断时间没有影响。我们对三代基准的实验,包括问题生成、合成和参数生成,表明拟议的框架为完全非偏移模型实现了新的最新结果。我们还表明,我们的方法可以用于各种预先培训的模型。例如,以经过培训的小型模型为基础的MIST也取得了与后代2eq模型相似的业绩。