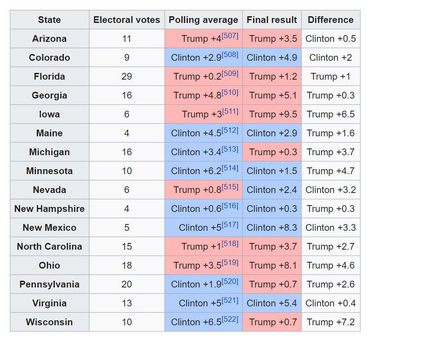
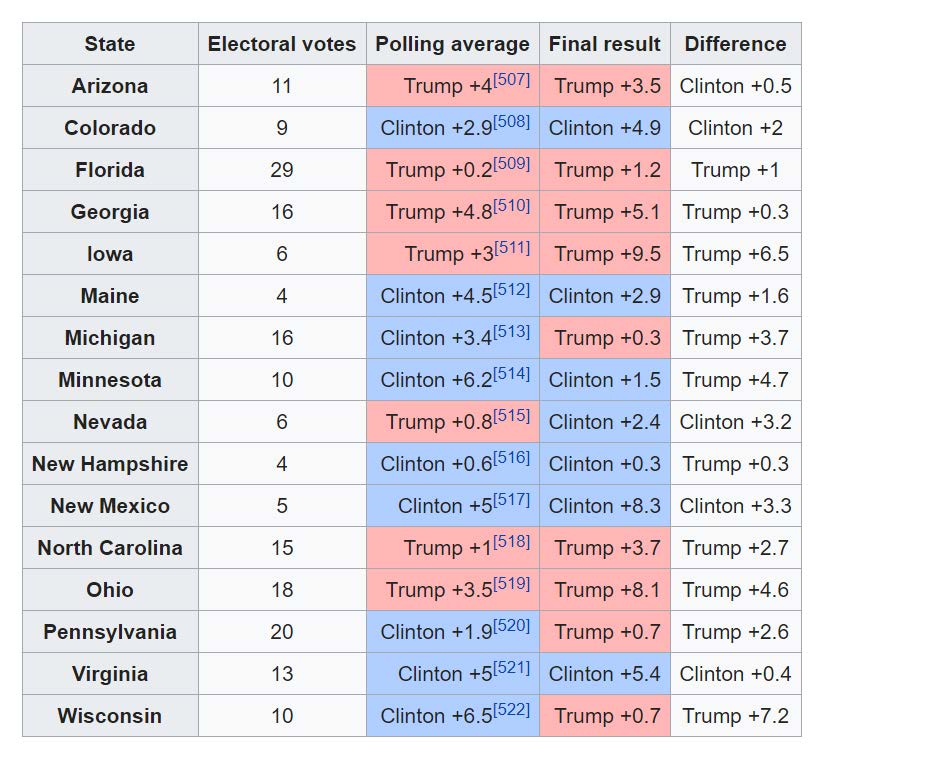
Donald Trump was lagging behind in nearly all opinion polls leading up to the 2016 US presidential election, but he surprisingly won the election. This raises the following important questions: 1) why most opinion polls were not accurate in 2016? and 2) how to improve the accuracies of opinion polls? In this paper, we study the inaccuracies of opinion polls in the 2016 election through the lens of information theory. We first propose a general framework of parameter estimation, called clean sensing (polling), which performs optimal parameter estimation with sensing cost constraints, from heterogeneous and potentially distorted data sources. We then cast the opinion polling as a problem of parameter estimation from potentially distorted heterogeneous data sources, and derive the optimal polling strategy using heterogenous and possibly distorted data under cost constraints. Our results show that a larger number of data samples do not necessarily lead to better polling accuracy, which give a possible explanation of the inaccuracies of opinion polls in 2016. The optimal sensing strategy should instead optimally allocate sensing resources over heterogenous data sources according to several factors including data quality, and, moreover, for a particular data source, it should strike an optimal balance between the quality of data samples, and the quantity of data samples. As a byproduct of this research, in a general setting, we derive a group of new lower bounds on the mean-squared errors of general unbiased and biased parameter estimators. These new lower bounds can be tighter than the classical Cram\'{e}r-Rao bound (CRB) and Chapman-Robbins bound. Our derivations are via studying the Lagrange dual problems of certain convex programs. The classical Cram\'{e}r-Rao bound and Chapman-Robbins bound follow naturally from our results for special cases of these convex programs.
翻译:唐纳德·特朗普(Donald Trump)在2016年美国总统选举前几乎所有民意测验中都落后于2016年美国总统选举,但令人惊讶地赢得了选举。这提出了以下重要问题:(1)为什么大多数民意测验在2016年不准确?和(2)如何改善民意测验的准确性?在本文件中,我们通过信息理论的透镜研究2016年选举民意测验的不准确性。我们首先提出了一个参数估计总框架,称为清洁感测(polling),它根据感测成本限制,从多种差异和可能扭曲的数据源中进行最佳参数估计。然后,我们把民意测验作为一个参数估算的问题,来自可能扭曲的混杂数据源,而我们则用杂乱的和可能扭曲的数据来得出最佳的双轨投票战略。我们的结果显示,更多的数据抽样不一定导致更好的民意测验准确性。 最优的感测战略应该根据包括数据质量在内的若干因素,并且对于特定的数据源来说,它应该达到一种最优的平衡性结果。我们从一个更精确的数据样本中得出一个普通的精确的样本和数量样本。