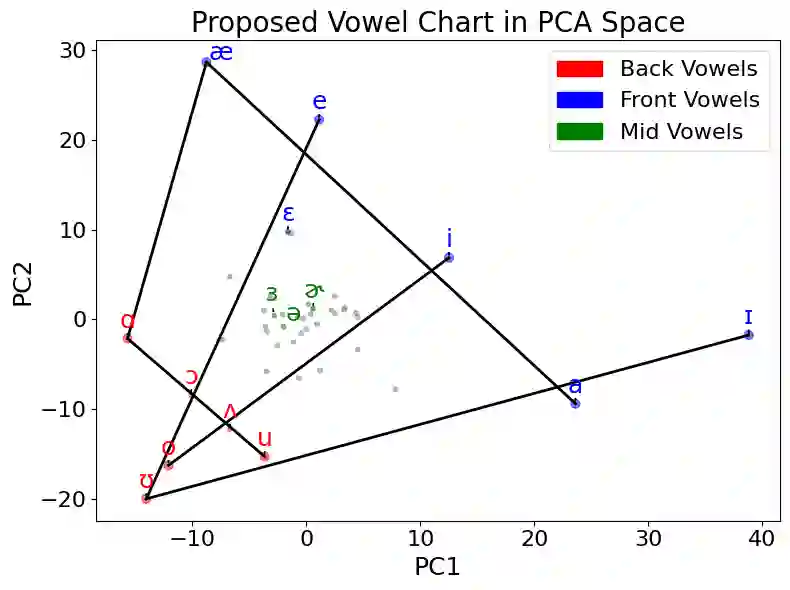
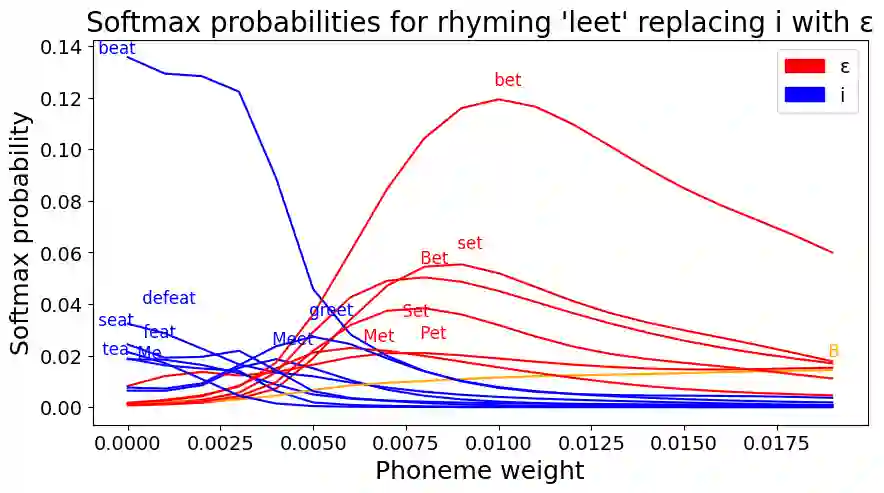
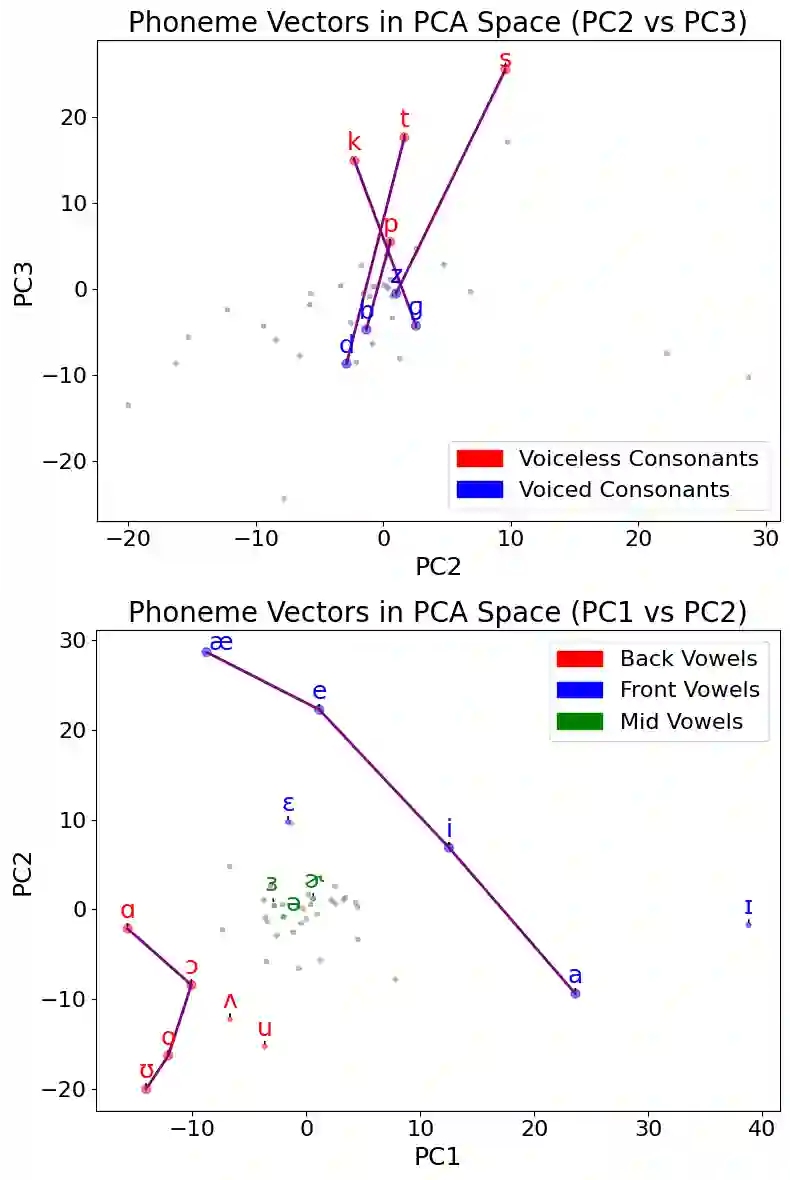
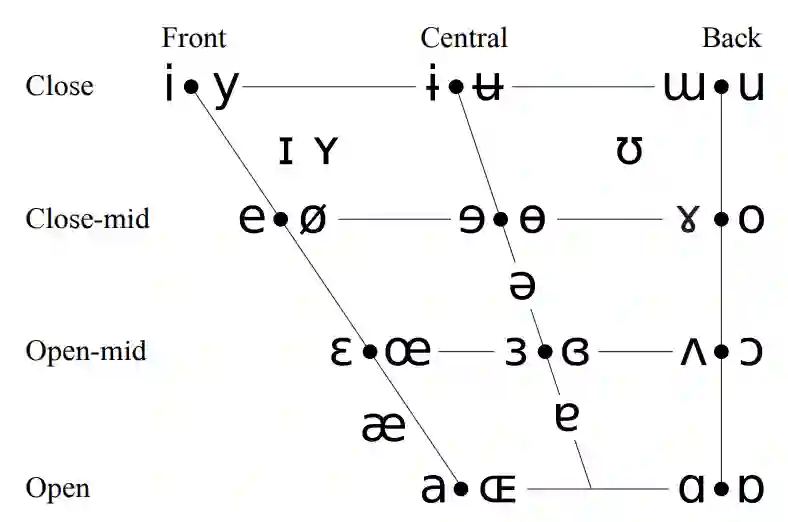
Large language models demonstrate proficiency on phonetic tasks, such as rhyming, without explicit phonetic or auditory grounding. In this work, we investigate how \verb|Llama-3.2-1B-Instruct| represents token-level phonetic information. Our results suggest that Llama uses a rich internal model of phonemes to complete phonetic tasks. We provide evidence for high-level organization of phoneme representations in its latent space. In doing so, we also identify a ``phoneme mover head" which promotes phonetic information during rhyming tasks. We visualize the output space of this head and find that, while notable differences exist, Llama learns a model of vowels similar to the standard IPA vowel chart for humans, despite receiving no direct supervision to do so.
翻译:大型语言模型在语音任务(如押韵)上表现出熟练能力,尽管其并未接受明确的语音或听觉基础训练。本研究探究了\verb|Llama-3.2-1B-Instruct|如何表征词元层级的语音信息。我们的结果表明,Llama利用丰富的内部音素模型来完成语音任务。我们为其潜在空间中音素表征的高层组织提供了证据。在此过程中,我们还识别出一个“音素迁移头”,该组件在押韵任务中促进语音信息的处理。我们可视化了该头的输出空间,发现尽管存在显著差异,Llama学习到的元音模型与人类使用的标准国际音标元音图相似,尽管其从未接受过直接监督以实现此目标。