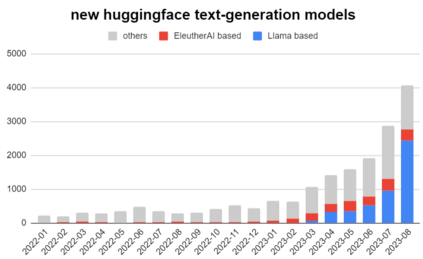
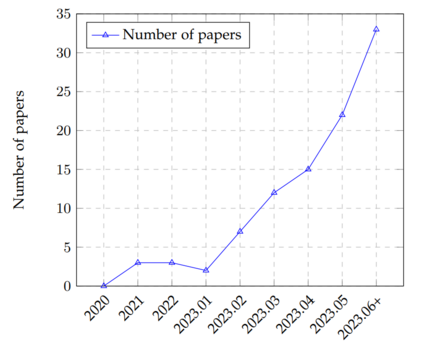
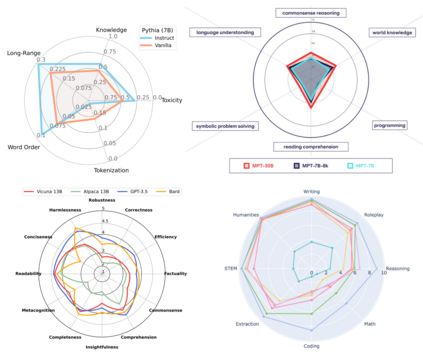
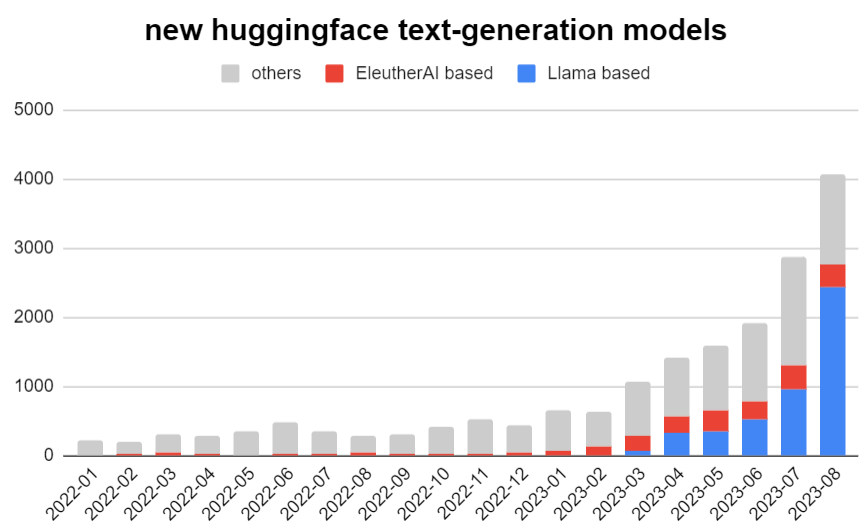
In the rapidly evolving landscape of Large Language Models (LLMs), introduction of well-defined and standardized evaluation methodologies remains a crucial challenge. This paper traces the historical trajectory of LLM evaluations, from the foundational questions posed by Alan Turing to the modern era of AI research. We categorize the evolution of LLMs into distinct periods, each characterized by its unique benchmarks and evaluation criteria. As LLMs increasingly mimic human-like behaviors, traditional evaluation proxies, such as the Turing test, have become less reliable. We emphasize the pressing need for a unified evaluation system, given the broader societal implications of these models. Through an analysis of common evaluation methodologies, we advocate for a qualitative shift in assessment approaches, underscoring the importance of standardization and objective criteria. This work serves as a call for the AI community to collaboratively address the challenges of LLM evaluation, ensuring their reliability, fairness, and societal benefit.
翻译:暂无翻译