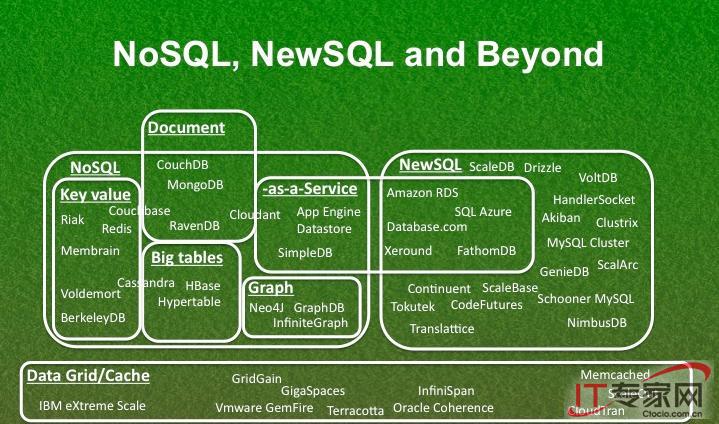
Google BigTable's scale-out design for distributed key-value storage inspired a generation of NoSQL databases. Recently the NewSQL paradigm emerged in response to analytic workloads that demand distributed computation local to data storage. Many such analytics take the form of graph algorithms, a trend that motivated the GraphBLAS initiative to standardize a set of matrix math kernels for building graph algorithms. In this article we show how it is possible to implement the GraphBLAS kernels in a BigTable database by presenting the design of Graphulo, a library for executing graph algorithms inside the Apache Accumulo database. We detail the Graphulo implementation of two graph algorithms and conduct experiments comparing their performance to two main-memory matrix math systems. Our results shed insight into the conditions that determine when executing a graph algorithm is faster inside a database versus an external system---in short, that memory requirements and relative I/O are critical factors.
翻译:Google BigTable用于分布式关键值存储的缩放设计启发了新一代的NOSQL数据库。最近,新SQL模式的出现是为了应对分析工作量,要求将分布式计算为本地数据存储。许多此类分析采用图表算法的形式,这一趋势促使GreabBLAS倡议将一组矩阵数学内核标准化,用于构建图形算法。在这个文章中,我们展示了如何在大表数据库中实施GreabBLAS内核,展示了Gapulo的设计,Gapulo是阿帕奇阿库穆洛数据库内一个执行图表算法的图书馆。我们详细介绍了两个图表算法的落实情况,并进行了实验,将其与两个主要模型数学系统进行比较。我们的结果揭示了在数据库中执行图表算法的速度要快于外部系统短短短的时间,而记忆要求和相对的I/O是关键因素。