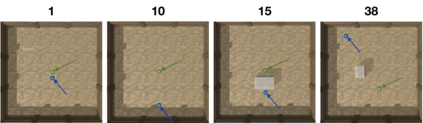
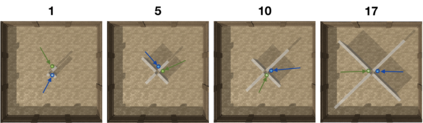
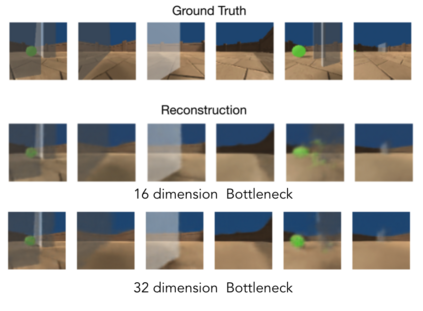
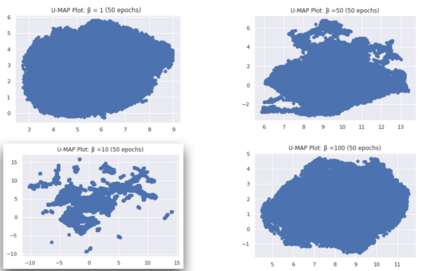
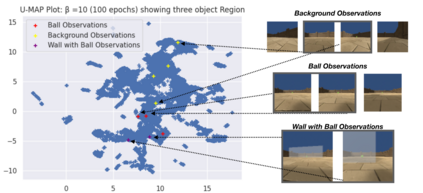
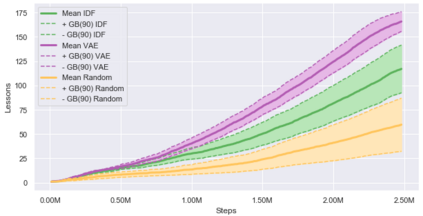
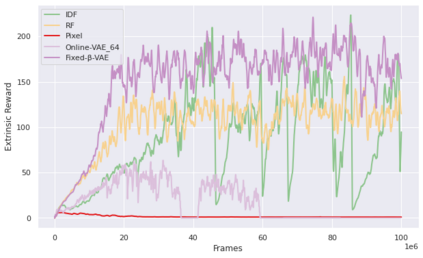
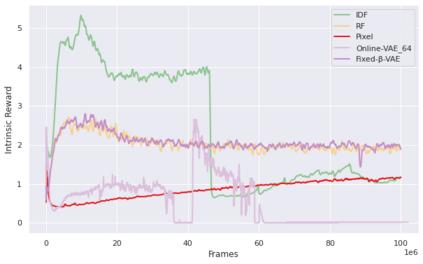
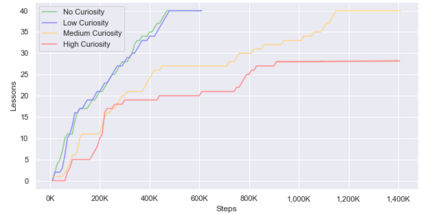
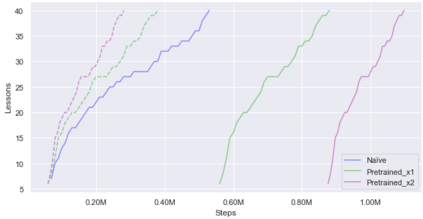
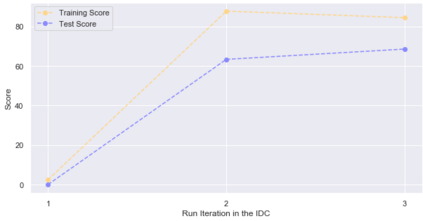
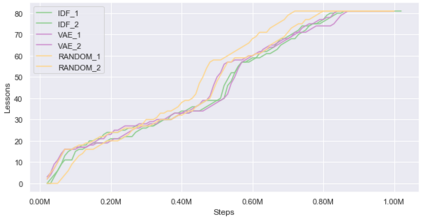
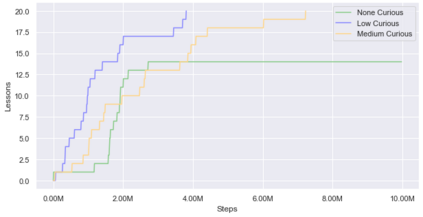
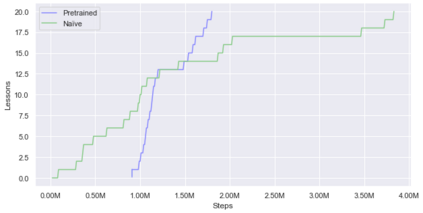
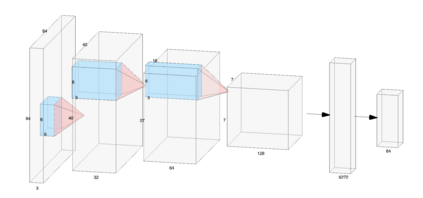
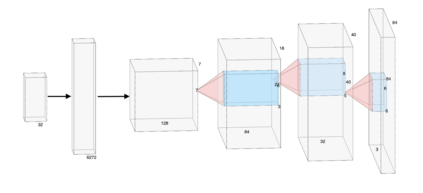
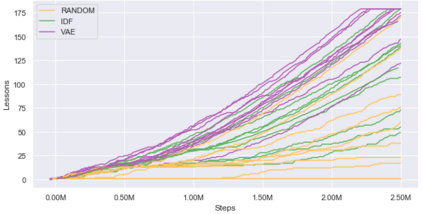
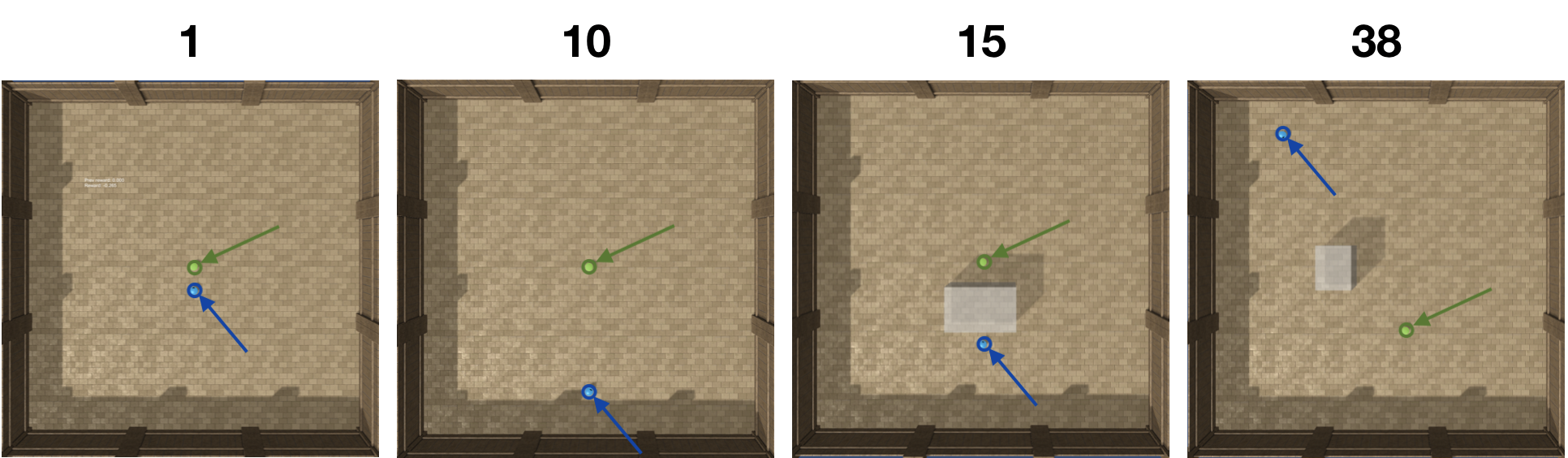
Curiosity is a general method for augmenting an environment reward with an intrinsic reward, which encourages exploration and is especially useful in sparse reward settings. As curiosity is calculated using next state prediction error, the type of state encoding used has a large impact on performance. Random features and inverse-dynamics features are generally preferred over VAEs based on previous results from Atari and other mostly 2D environments. However, unlike VAEs, they may not encode sufficient information for optimal behaviour, which becomes increasingly important as environments become more complex. In this paper, we use the sparse reward 3D physics environment Animal-AI, to demonstrate how a fixed $\beta$-VAE encoding can be used effectively with curiosity. We combine this with curriculum learning to solve the previously unsolved exploration intensive detour tasks while achieving 22\% gain in sample efficiency on the training curriculum against the next best encoding. We also corroborate the results on Atari Breakout, with our custom encoding outperforming random features and inverse-dynamics features.
翻译:好奇是增加环境奖赏的一般方法,具有内在奖赏,鼓励勘探,在稀有的奖赏环境中特别有用。由于好奇心是使用下一个状态预测错误计算出来的,因此使用的状态编码类型对性能有很大影响。根据Atari和其他大多数为2D环境的先前结果,随机特征和反动特性通常优于VAEs。然而,不同于VAEs,它们可能无法将足够的信息编码为最佳行为,而最佳行为随着环境变得更加复杂而变得日益重要。在本文中,我们使用稀有的3D物理环境动物-AI奖赏,以展示固定的$\beta$-VAE编码如何能以好奇心有效使用。我们将此与课程学习相结合,以解决先前尚未解析的勘探密集型绕行任务,同时实现22 ⁇ 在培训课程中取得相对于下一个最佳编码的样本效率。我们还证实了关于Atari Brebout的结果,我们习惯编码的随机特征和反动动特性。