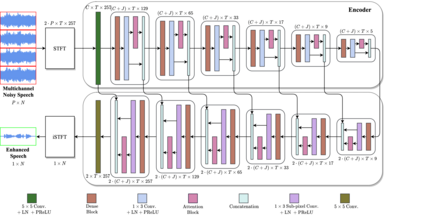
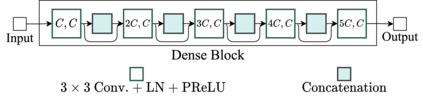
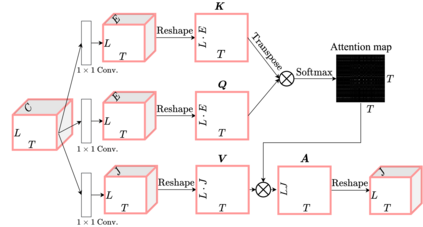
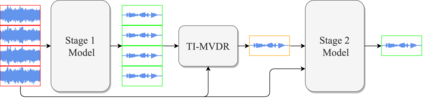
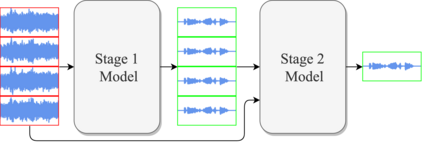
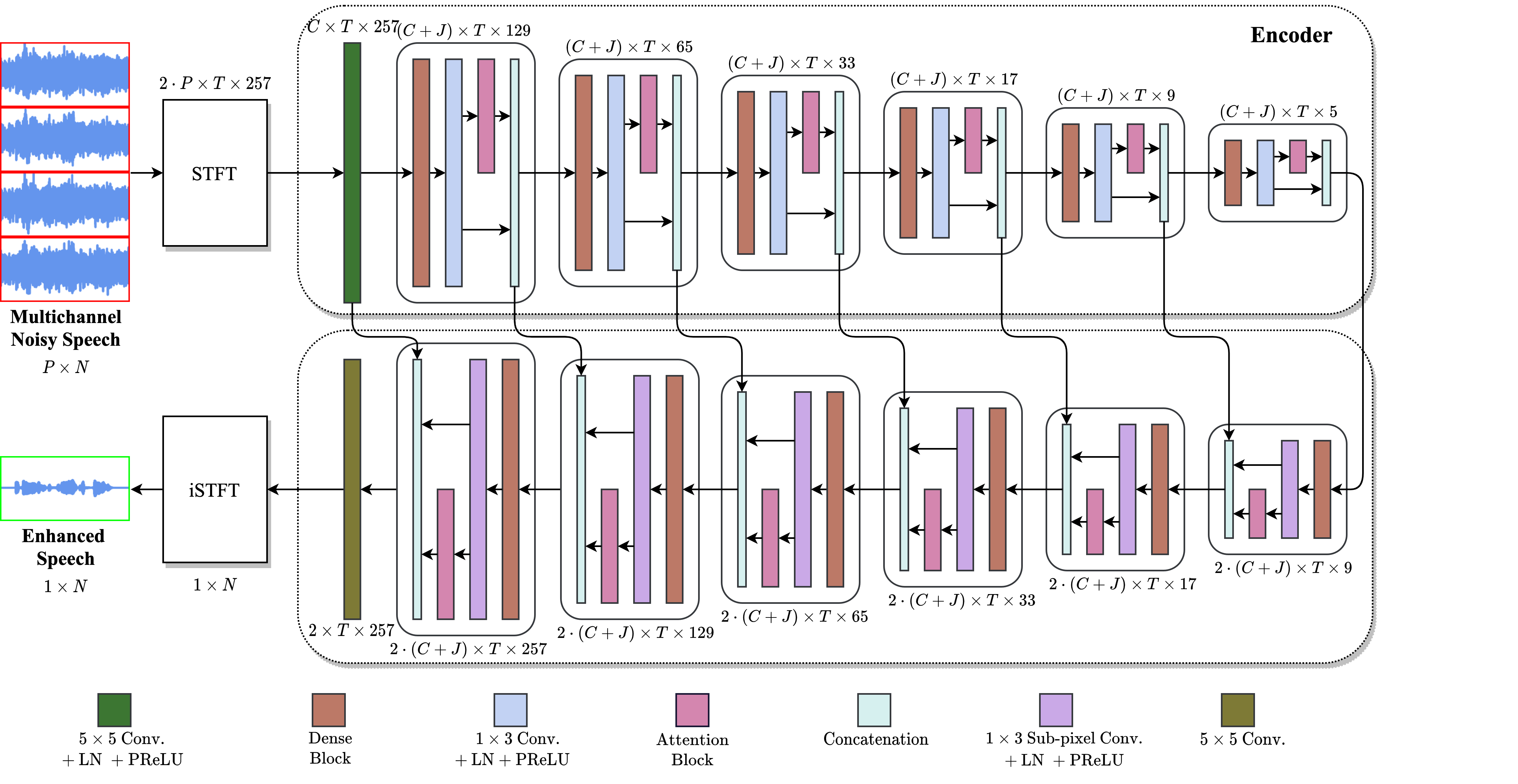
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
翻译:深神经网络往往与传统的空间过滤器相伴,如用于有效利用空间信息的MVDR光谱仪等传统空间过滤器。即使单阶段端到端监督模型能够取得令人印象深刻的增强,同时在多阶段处理中将这些模型与光源和基于DNN的后过滤器相结合,可以带来更多的改进。在这项工作中,我们提出了多频道语音增强的两阶段战略,不需要以光谱仪作为额外性能的信号。首先,我们提议建立一个新颖的注意密集的共振网络(ADCN),用于预测复杂光谱的真实和想象部分。ADCN在单阶段模型中获得了最先进的结果。接下来,我们利用拟议战略中的ADCN(ADCN)和最近提议的三重心经常性网络(TPARN)来预测波形样本。拟议战略使用两种洞察力;首先,在两个阶段使用不同的方法;第二,在第一阶段使用更强的模型。我们用两个阶段评价多种模型来说明我们的战略的功效。我们用两个阶段的方法来评价多种模型,而不用瞄准。