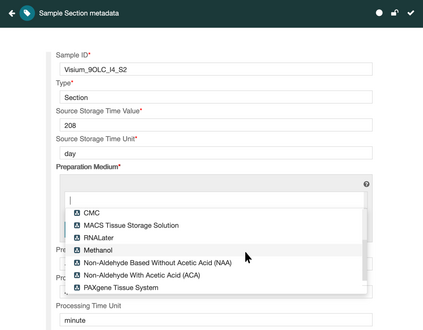
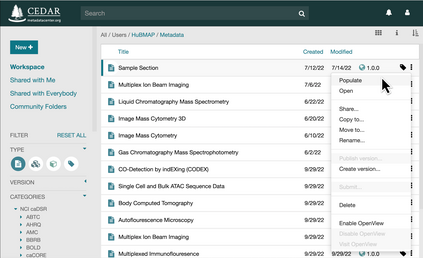
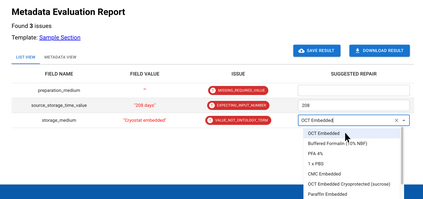
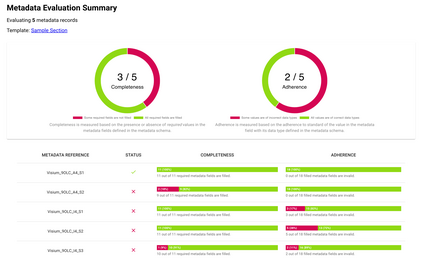
It is challenging to determine whether datasets are findable, accessible, interoperable, and reusable (FAIR) because the FAIR Guiding Principles refer to highly idiosyncratic criteria regarding the metadata used to annotate datasets. Specifically, the FAIR principles require metadata to be "rich" and to adhere to "domain-relevant" community standards. Scientific communities should be able to define their own machine-actionable templates for metadata that encode these "rich," discipline-specific elements. We have explored this template-based approach in the context of two software systems. One system is the CEDAR Workbench, which investigators use to author new metadata. The other is the FAIRware Workbench, which evaluates the metadata of archived datasets for their adherence to community standards. Benefits accrue when templates for metadata become central elements in an ecosystem of tools to manage online datasets--both because the templates serve as a community reference for what constitutes FAIR data, and because they embody that perspective in a form that can be distributed among a variety of software applications to assist with data stewardship and data sharing.
翻译:确定数据集是否可找到、可获取、可互操作和可重复使用(FAIR)是具有挑战性的,因为FAIR《指导原则》提及关于用于说明数据集的元数据的高度特异性标准。具体地说,FAIR原则要求元数据“丰富”并遵守“与域有关”的社区标准。科学界应当能够为编码这些“丰富”、学科特定要素的元数据确定自己的机器可操作模板。我们已经在两个软件系统中探索了这种基于模板的方法。一个系统是CEDAR Workbench,调查人员用来撰写新的元数据。另一个系统是FAIRware Workbench,评估存档数据集的元数据是否符合社区标准。当元数据模板成为管理在线数据集的生态系统工具的核心要素时,将产生效益,因为这些模板是构成FAIR数据的一个社区参考工具,并体现这种观点的形式可以分布在各种软件应用程序中,以协助数据管理和数据共享。