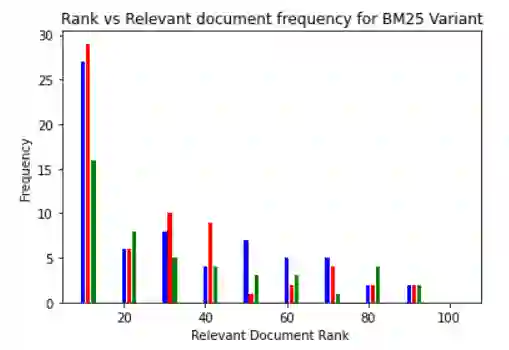
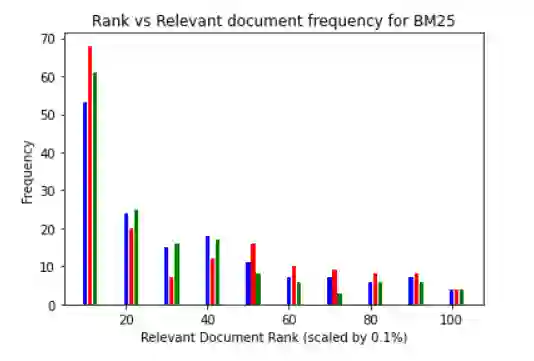
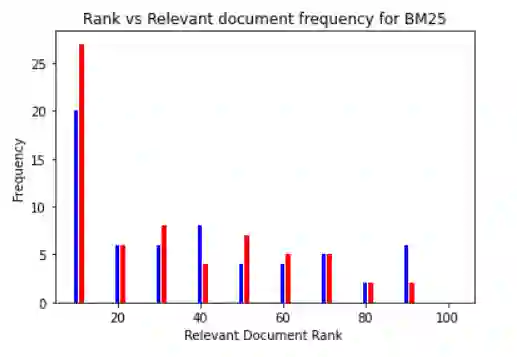
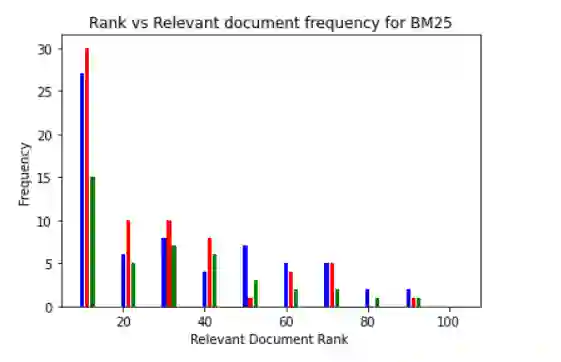
Document retrieval has taken its role in almost all domains of knowledge understanding, including the legal domain. Precedent refers to a court decision that is considered as authority for deciding subsequent cases involving identical or similar facts or similar legal issues. In this work, we propose different unsupervised approaches to solve the task of identifying relevant precedents to a given query case. Our proposed approaches are using word embeddings like word2vec, doc2vec, and sent2vec, finding cosine similarity using TF-IDF, retrieving relevant documents using BM25 scores, using the pre-trained model and SBERT to find the most similar document, and using the product of BM25 and TF-IDF scores to find the most relevant document for a given query. We compared all the methods based on precision@10, recall@10, and MRR. Based on the comparative analysis, we found that the TF-IDF score multiplied by the BM25 score gives the best result. In this paper, we have also presented the analysis that we did to improve the BM25 score.
翻译:在这项工作中,我们提出了不同的未经监督的方法,以解决确定某一查询案例相关先例的任务。我们建议的方法是使用Word2vec、Doc2vec和Sent2vec等词嵌入词,利用TF-IDF找到相似之处,利用TF-IDF找到使用BM25分数的相似性,利用BM25分数检索相关文件,利用预先培训的模型和SBERT找到最相似的文件,并利用BM25和TF-IDF分数的产物为特定查询找到最相关的文件。我们比较了所有基于精确@10、回顾@10和MRRR的方法。根据比较分析,我们发现TF-IDF分数乘以BM25分数得出了最佳结果。在这份文件中,我们还介绍了改进BM25分数的分析。