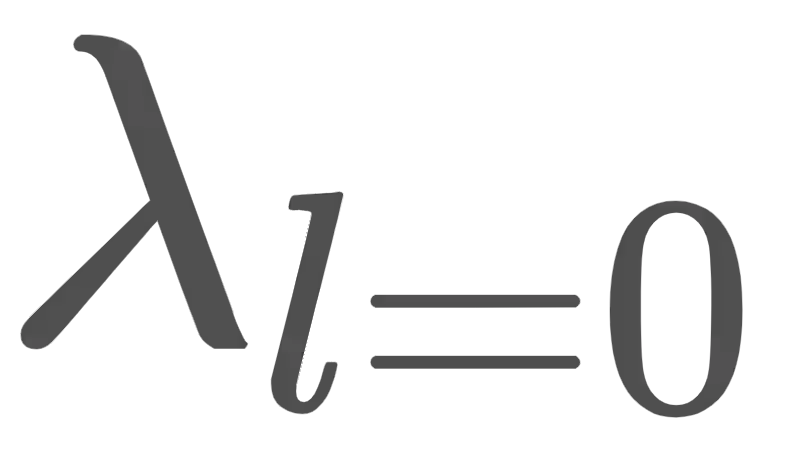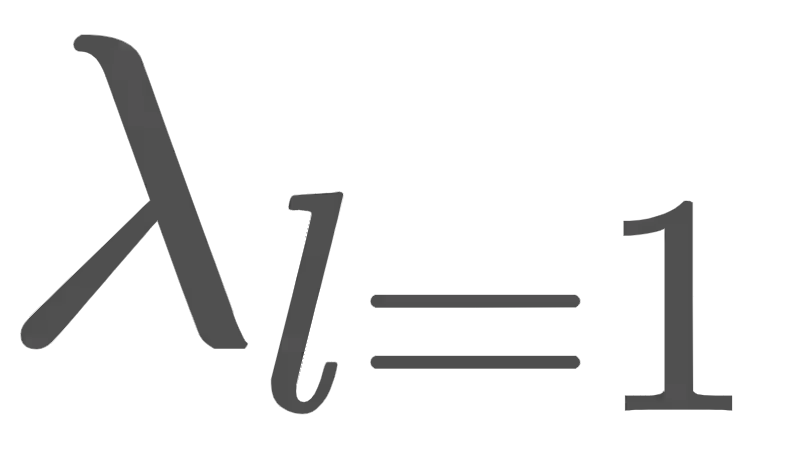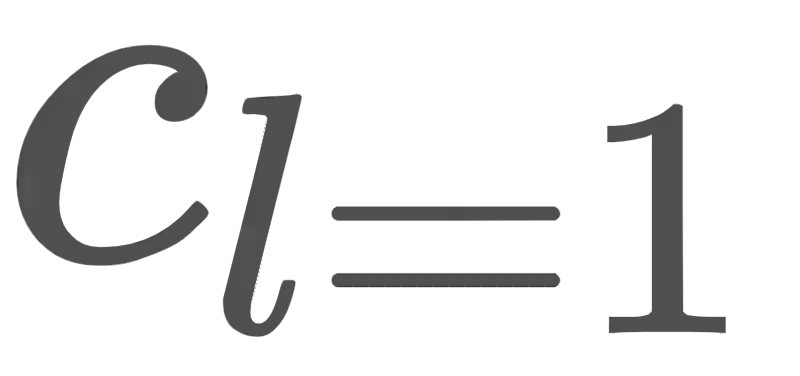In this paper, we propose a method for intermediating multiple speakers' attributes and diversifying their voice characteristics in ``speaker generation,'' an emerging task that aims to synthesize a nonexistent speaker's naturally sounding voice. The conventional TacoSpawn-based speaker generation method represents the distributions of speaker embeddings by Gaussian mixture models (GMMs) conditioned with speaker attributes. Although this method enables the sampling of various speakers from the speaker-attribute-aware GMMs, it is not yet clear whether the learned distributions can represent speakers with an intermediate attribute (i.e., mid-attribute). To this end, we propose an optimal-transport-based method that interpolates the learned GMMs to generate nonexistent speakers with mid-attribute (e.g., gender-neutral) voices. We empirically validate our method and evaluate the naturalness of synthetic speech and the controllability of two speaker attributes: gender and language fluency. The evaluation results show that our method can control the generated speakers' attributes by a continuous scalar value without statistically significant degradation of speech naturalness.
翻译:在本文中,我们提出了一种在“扩音器一代”中将多个发言者的属性和声音特征多样化的中间媒介方法,这是一项新兴任务,旨在合成一个不存在的发言者自然声音。传统TacoSpawn的扩音器生成方法代表了按发言者属性条件由高斯混合模型嵌入的发言者的分布。虽然这种方法使得能够对发言者来自GMMMS的组合进行抽样,但尚不清楚所学到的分发方法能否以中间属性(即中属性)代表发言者。为此,我们提出了一种基于运输的最佳方法,将所学到的GMMS用于中间属性(例如,性别中性)生成不存在的发言者。我们从经验上验证了我们的方法,评价了合成语音的自然性以及两个发言者属性的可控制性:性别和语言流利。评价结果表明,我们的方法可以通过连续的斜度价值来控制发言者的属性,而不会在统计上显著地降低语言自然性。