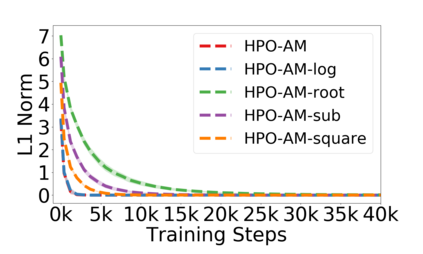
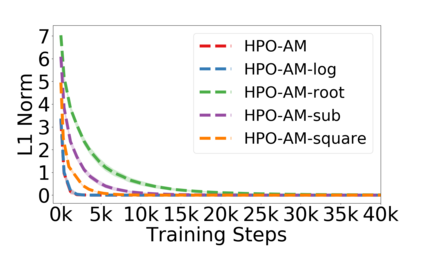
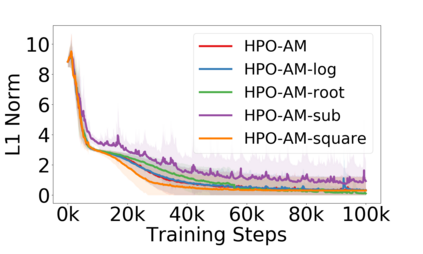
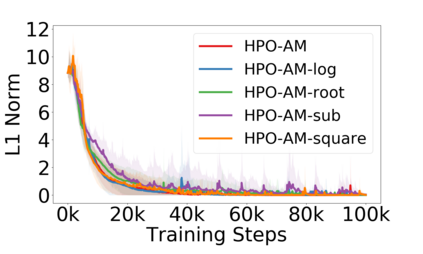
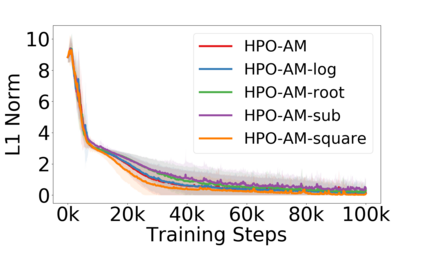
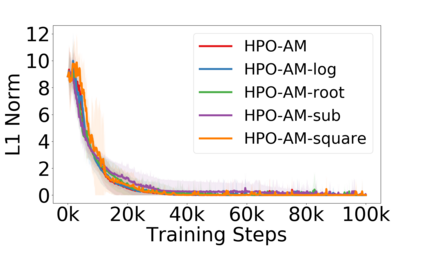
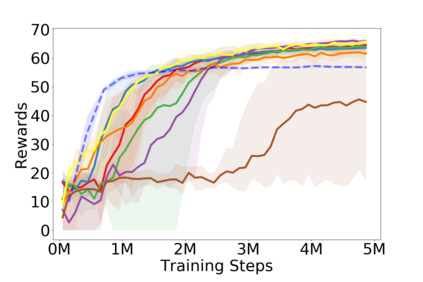
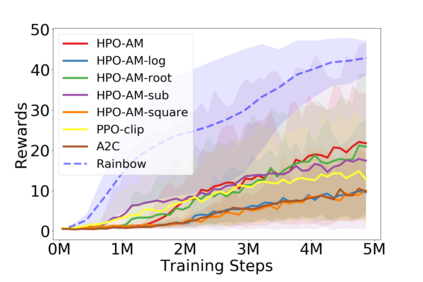
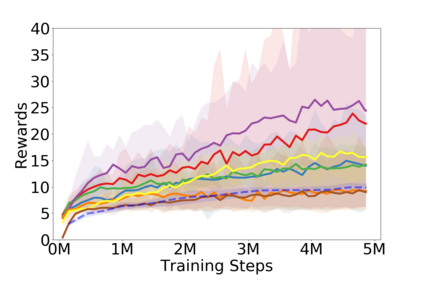
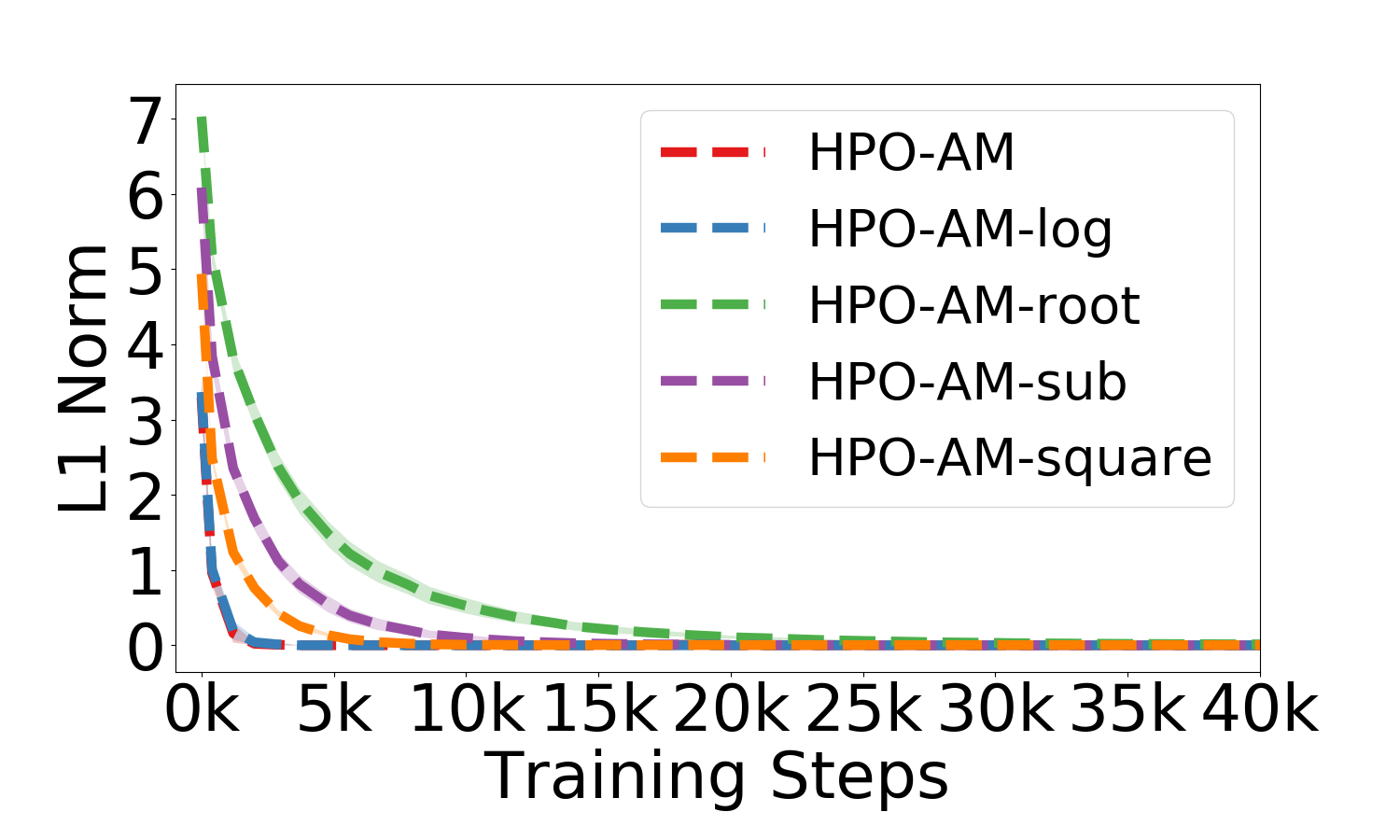
Policy optimization is a fundamental principle for designing reinforcement learning algorithms, and one example is the proximal policy optimization algorithm with a clipped surrogate objective (PPO-clip), which has been popularly used in deep reinforcement learning due to its simplicity and effectiveness. Despite its superior empirical performance, PPO-clip has not been justified via theoretical proof up to date. This paper proposes to rethink policy optimization and reinterpret the theory of PPO-clip based on hinge policy optimization (HPO), called to improve policy by hinge loss in this paper. Specifically, we first identify sufficient conditions of state-wise policy improvement and then rethink policy update as solving a large-margin classification problem with hinge loss. By leveraging various types of classifiers, the proposed design opens up a whole new family of policy-based algorithms, including the PPO-clip as a special case. Based on this construct, we prove that these algorithms asymptotically attain a globally optimal policy. To our knowledge, this is the first ever that can prove global convergence to an optimal policy for a variant of PPO-clip. We corroborate the performance of a variety of HPO algorithms through experiments and an ablation study.
翻译:政策优化是设计强化学习算法的一项基本原则,其中一个例子就是具有剪接代孕目标(PPO-clip)的近似政策优化算法(POPO-clip),由于它的简单性和有效性,在深入强化学习中广泛使用。尽管PPO-clip表现优异,但通过最新的理论证据,PPO-clip没有正当理由。本文件建议重新思考政策优化,重新解释基于关键政策优化(HPO-clip)的PPPO-clip理论(HPO-clip)的理论,该理论被呼吁通过本文中的损失来改善政策。具体地说,我们首先确定国家政策改进的充分条件,然后重新思考政策更新政策更新,作为解决以临界损失为基础的大边际分类问题。通过利用各种分类师,拟议的设计开启了基于政策的各种新的算法,包括PPPO-clip作为特例。基于这一构思,我们证明这些算算算算算算算算出全球最佳政策。据我们所知,这是第一次证明全球对PPO-clip研究的最佳政策具有最佳趋一致性。我们通过一种实验和一种实验证实了各种HPOallallals的绩效。