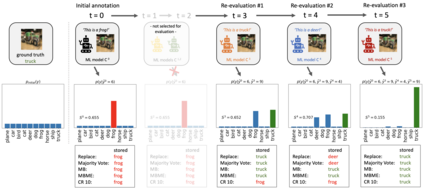
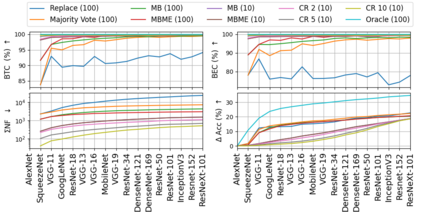
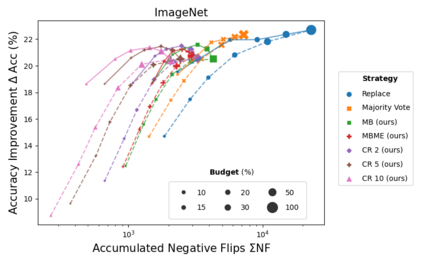
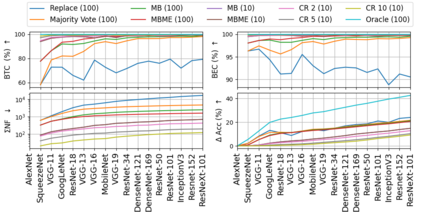
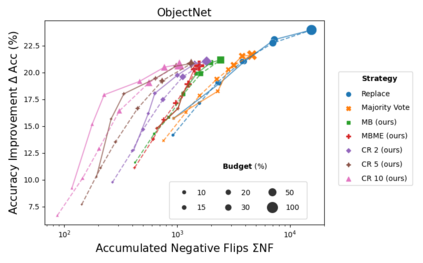
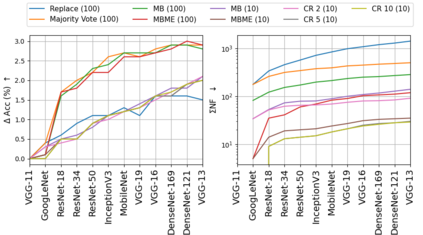
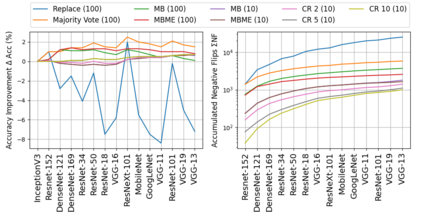
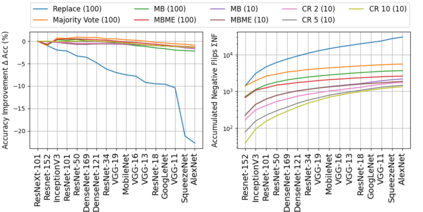
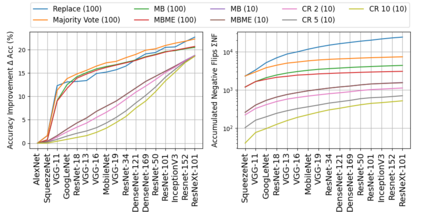
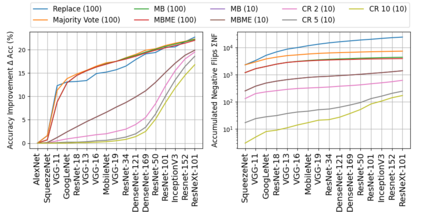
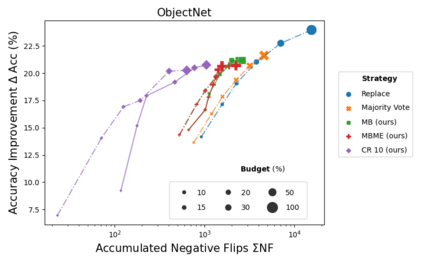
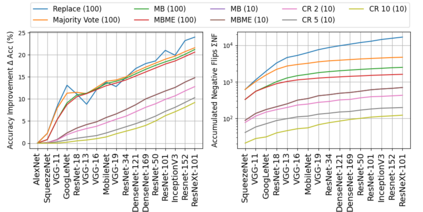
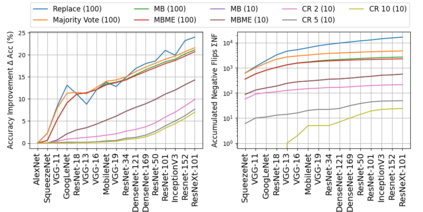
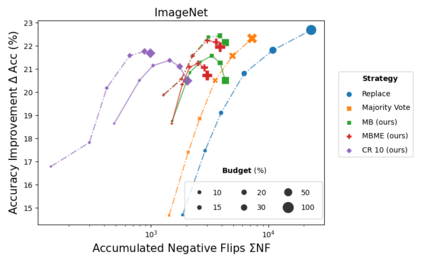
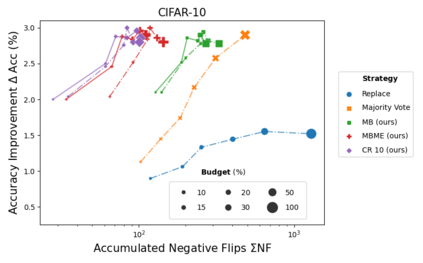
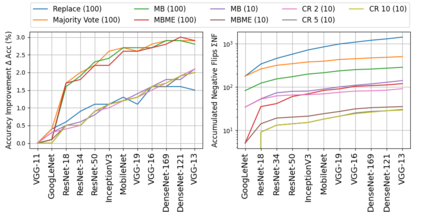
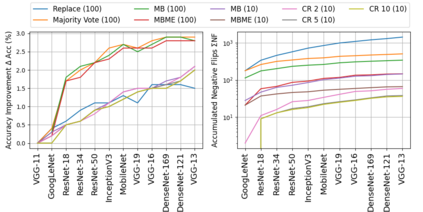
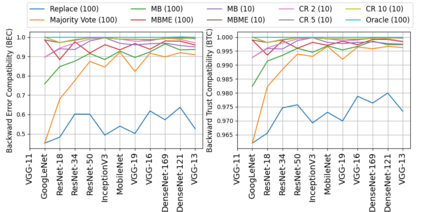
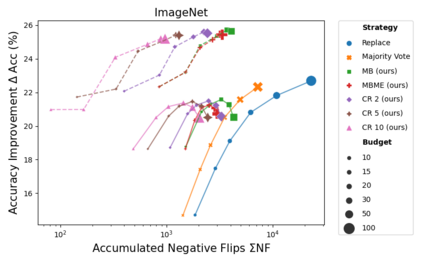
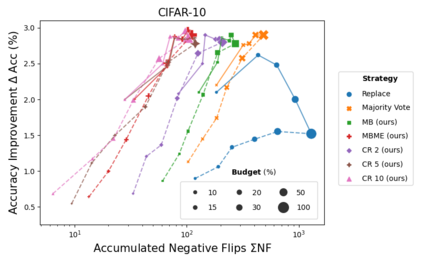
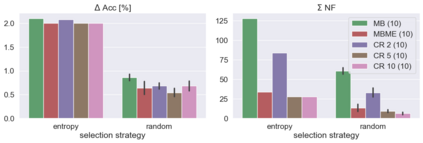
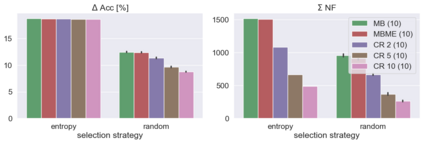
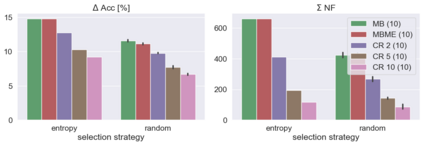
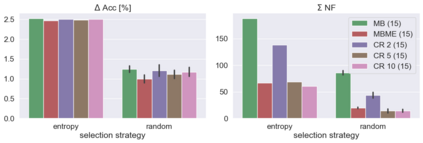
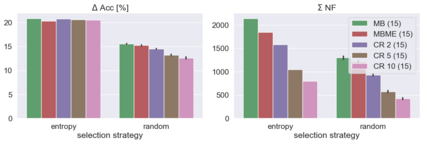
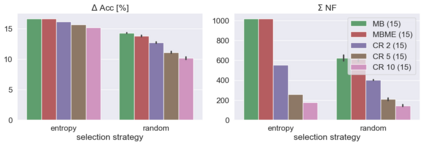
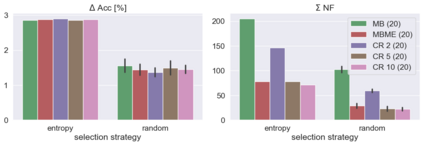
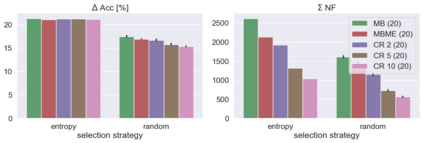
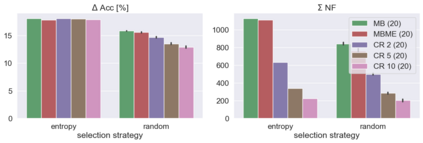
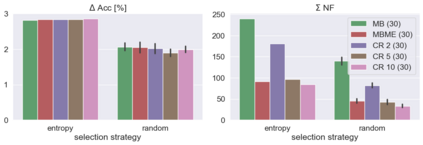
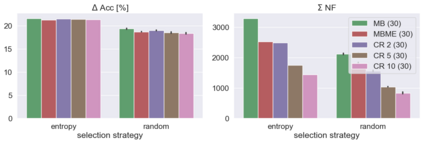
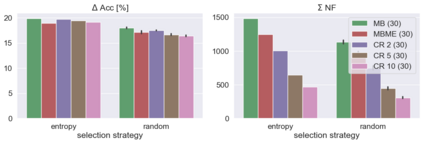
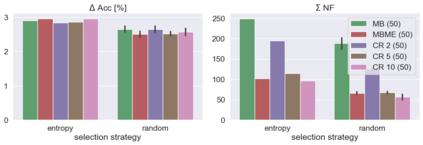
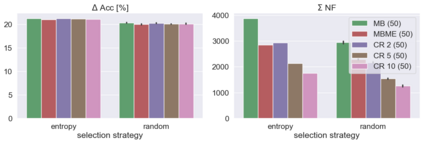
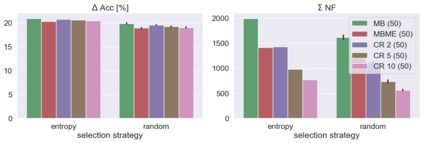
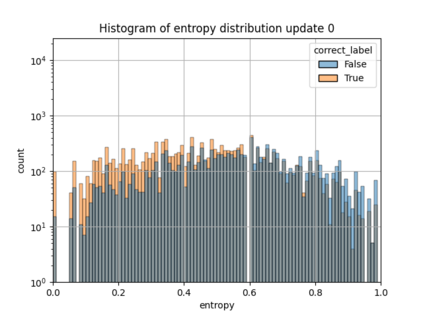
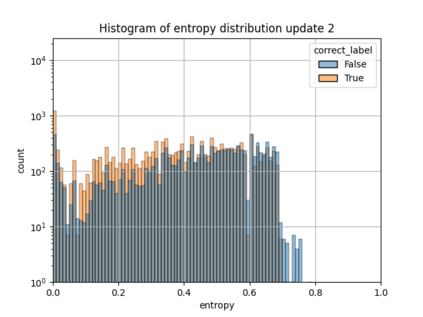
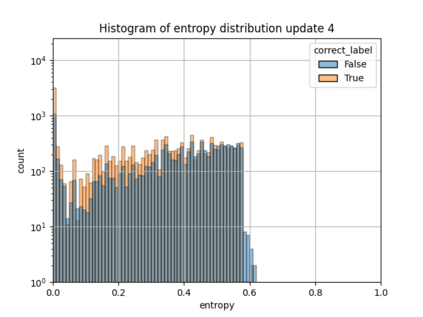
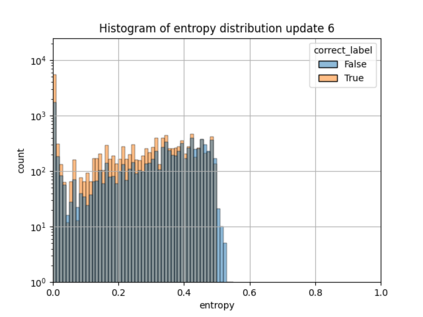
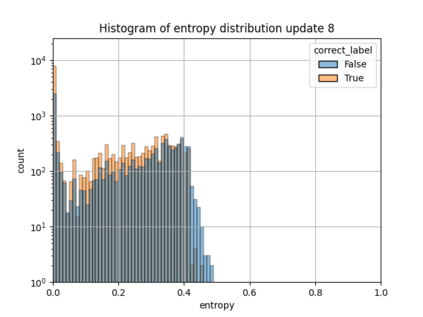
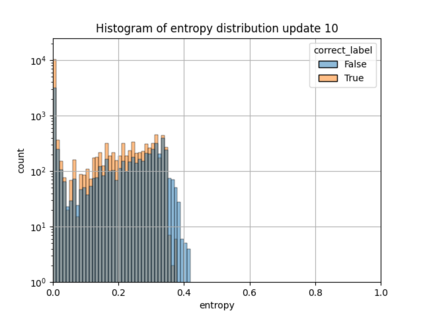
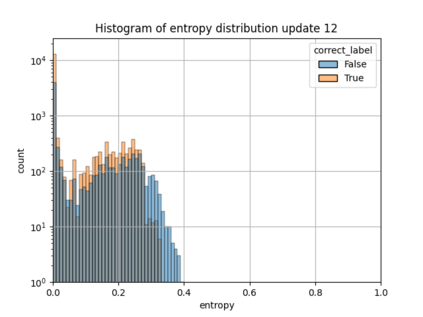
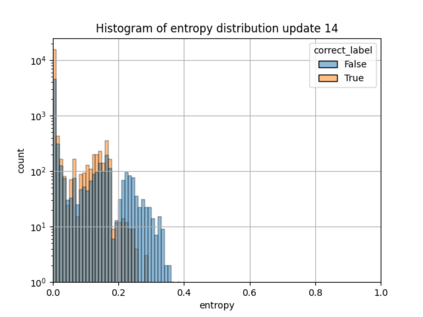
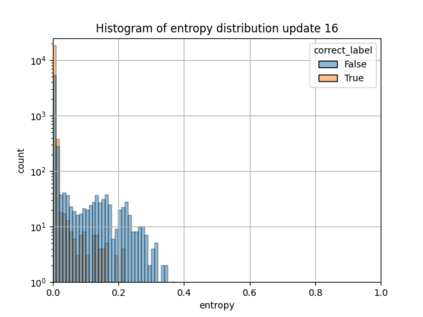
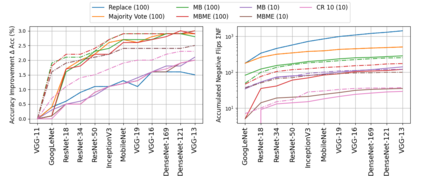
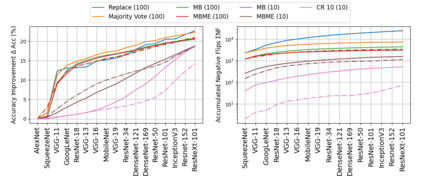
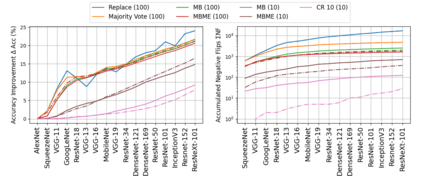
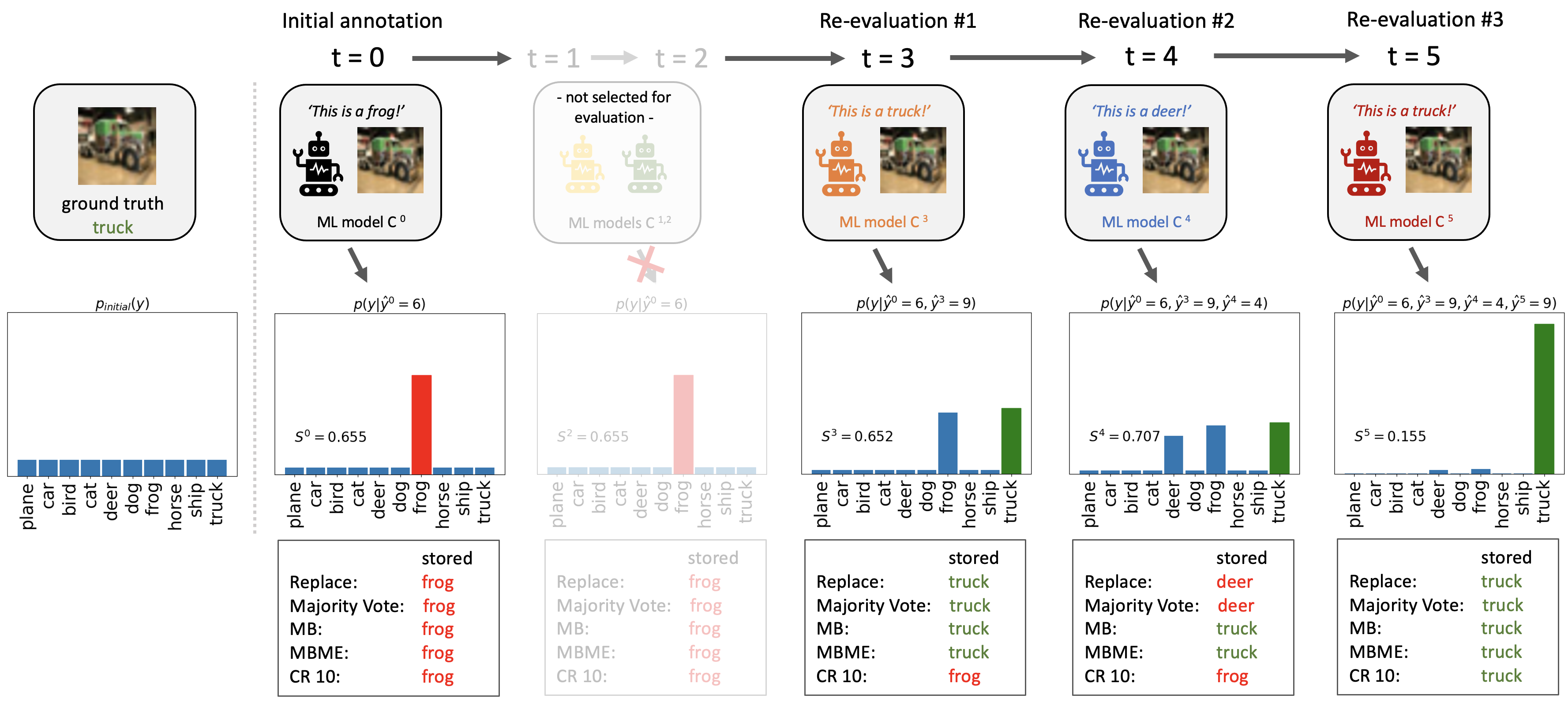
When machine learning systems meet real world applications, accuracy is only one of several requirements. In this paper, we assay a complementary perspective originating from the increasing availability of pre-trained and regularly improving state-of-the-art models. While new improved models develop at a fast pace, downstream tasks vary more slowly or stay constant. Assume that we have a large unlabelled data set for which we want to maintain accurate predictions. Whenever a new and presumably better ML models becomes available, we encounter two problems: (i) given a limited budget, which data points should be re-evaluated using the new model?; and (ii) if the new predictions differ from the current ones, should we update? Problem (i) is about compute cost, which matters for very large data sets and models. Problem (ii) is about maintaining consistency of the predictions, which can be highly relevant for downstream applications; our demand is to avoid negative flips, i.e., changing correct to incorrect predictions. In this paper, we formalize the Prediction Update Problem and present an efficient probabilistic approach as answer to the above questions. In extensive experiments on standard classification benchmark data sets, we show that our method outperforms alternative strategies along key metrics for backward-compatible prediction updates.
翻译:当机器学习系统满足现实世界应用时,精确度只是几个要求之一。在本文中,我们从越来越多的预先培训和定期改进最新模型的可得性的角度分析出一个互补的视角。新的改良模型发展得很快,下游任务则较为缓慢或保持不变。假设我们有一个庞大的无标签数据集,我们希望保持准确的预测。当出现新的和可能更好的ML模型时,我们遇到两个问题:(一) 预算有限,应当使用新的模型重新评价哪些数据点?和(二) 如果新的预测与当前预测不同,我们应该更新吗?问题(一) 是计算成本,对于非常大型的数据集和模型很重要。问题(二) 是保持预测的一致性,对于下游应用来说,这可能非常相关;我们的要求是避免负面翻转,即改变错误的预测。在本文中,我们将预测更新问题正式化了预测最新数据,并提出一种高效的替代方法,用以回答上述问题。在进行广泛的标准分类时,我们按照可变式基准数据格式进行基础分析时,我们展示了一种可变式的精确的预测方法。