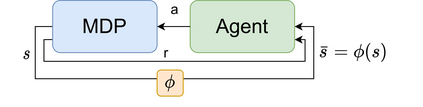
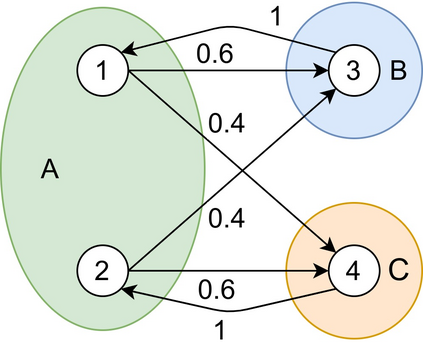
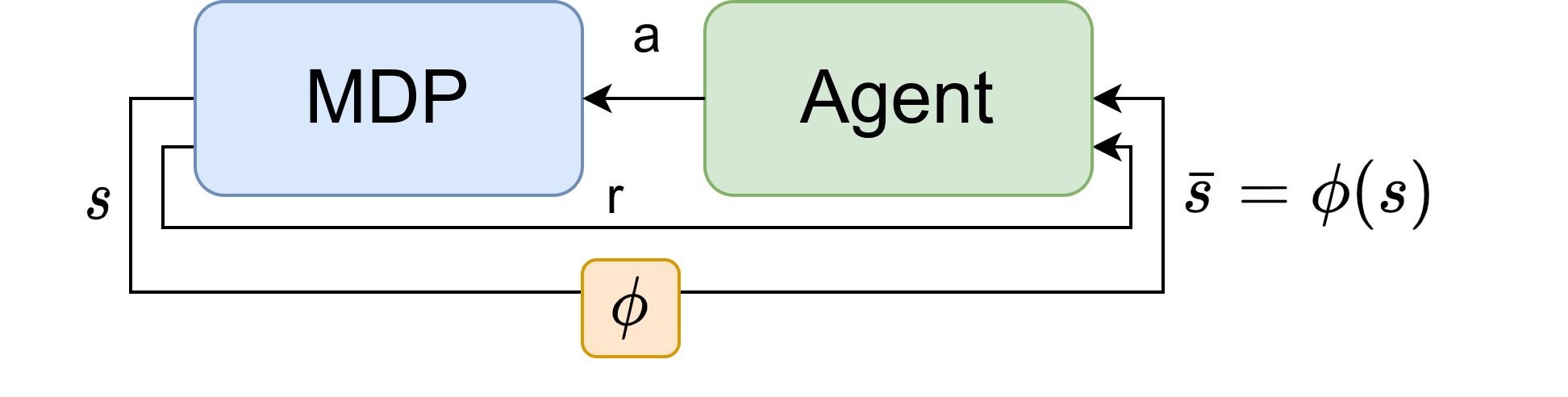
Many methods for Model-based Reinforcement learning (MBRL) provide guarantees for both the accuracy of the Markov decision process (MDP) model they can deliver and the learning efficiency. At the same time, state abstraction techniques allow for a reduction of the size of an MDP while maintaining a bounded loss with respect to the original problem. It may come as a surprise, therefore, that no such guarantees are available when combining both techniques, i.e., where MBRL merely observes abstract states. Our theoretical analysis shows that abstraction can introduce a dependence between samples collected online (e.g., in the real world), which means that most results for MBRL can not be directly extended to this setting. The new results in this work show that concentration inequalities for martingales can be used to overcome this problem and allows for extending the results of algorithms such as R-MAX to the setting with abstraction. Thus producing the first performance guarantees for Abstracted RL: model-based reinforcement learning with an abstracted model.
翻译:以模型为基础的强化学习(MBRL)的许多方法为Markov决定程序(MDP)模型的准确性和学习效率提供了保障。与此同时,国家抽象技术允许缩小MDP的大小,同时保持与原始问题有关的受约束损失。因此,在将这两种技术相结合时,例如MBRL只观察抽象状态时,可能令人惊讶的是,没有这种保障。我们的理论分析表明,抽象化可以在网上收集的样本(例如,在现实世界中)之间引入依赖性,这意味着MBRL的大多数结果不能直接延伸到这一环境。这项工作的新结果表明,可以使用马丁加勒的浓度不平等来克服这一问题,并允许将R-MAX等算法的结果扩大到带有抽象的设置。因此产生了对抽象的RL:基于模型的强化学习的第一个性能保证。