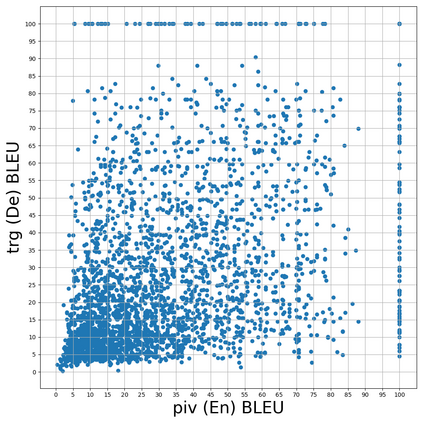
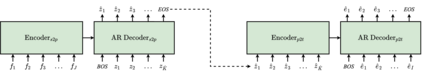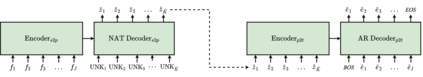Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
翻译:低资源设置中通常使用基于神经的神经机器翻译(NMT),特别是用于非英语语言对口的翻译;使用高资源源源源-pivot和Pivot目标语言对口,对两个子任务都进行单独系统的培训,但这些模型在培训期间没有连接,源-pivot模型也没有优化,无法为源-目标任务提供最佳翻译;在这项工作中,我们提议用强化学习(RL)方法来培训基于枢纽的NMT系统,该方法已经对包括机器翻译在内的各种文本生成任务进行了调查。我们使用了一种不偏向变异器,并提出了一个基于源-目标数据的终端-端集成综合模型,使源-目标数据培训成为可能。