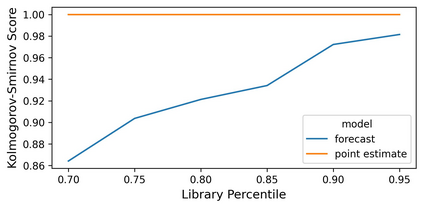
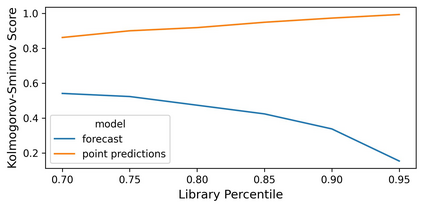
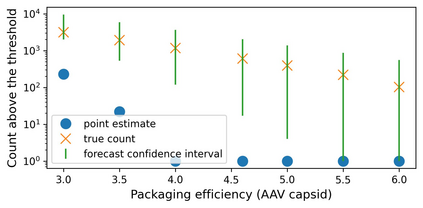
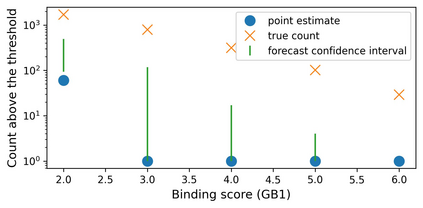
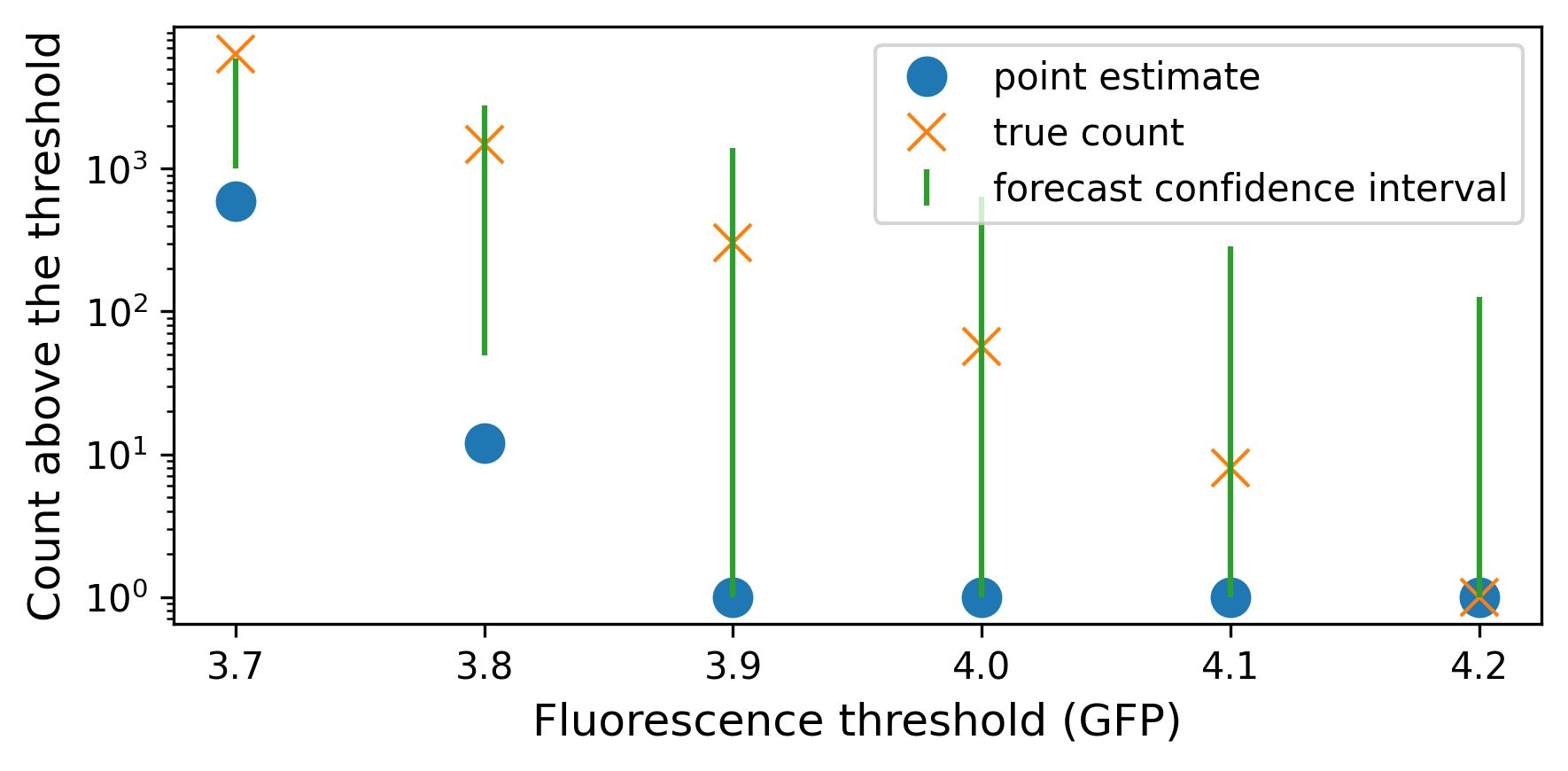
The ability to design and optimize biological sequences with specific functionalities would unlock enormous value in technology and healthcare. In recent years, machine learning-guided sequence design has progressed this goal significantly, though validating designed sequences in the lab or clinic takes many months and substantial labor. It is therefore valuable to assess the likelihood that a designed set contains sequences of the desired quality (which often lies outside the label distribution in our training data) before committing resources to an experiment. Forecasting, a prominent concept in many domains where feedback can be delayed (e.g. elections), has not been used or studied in the context of sequence design. Here we propose a method to guide decision-making that forecasts the performance of high-throughput libraries (e.g. containing $10^5$ unique variants) based on estimates provided by models, providing a posterior for the distribution of labels in the library. We show that our method outperforms baselines that naively use model scores to estimate library performance, which are the only tool available today for this purpose.
翻译:设计和优化具有特定功能的生物序列的能力将释放技术和医疗保健的巨大价值。近年来,机器学习指导序列设计已经大大推进了这一目标,尽管验证实验室或诊所的设计序列需要许多个月和大量劳动。因此,在将资源投入实验之前,评估设计数据集包含所需质量序列的可能性(通常不在我们培训数据标签分发范围之内)是有价值的。 预测是许多领域的一个突出概念,可以延迟反馈(例如选举),但在序列设计方面没有使用或研究过。 我们在这里提出了一个方法,用以指导决策,根据模型提供的估计数预测高通量图书馆的性能(例如包含10 5美元的独特变量),为图书馆的标签分配提供一个海报。我们显示,我们的方法超越了天真地使用模型分数来估计图书馆业绩的基线,而图书馆业绩是目前用于此目的的唯一工具。