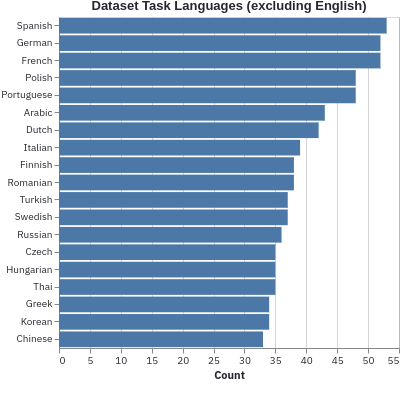
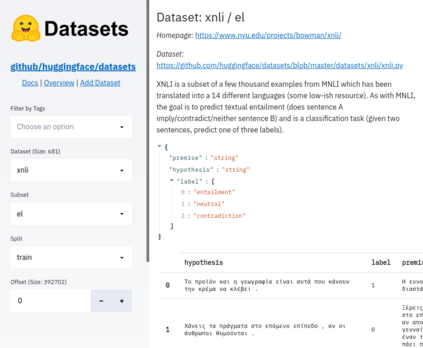
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
翻译:随着研究人员提出新的任务、更大的模型和新的基准,公众可公开获得的NLP数据集的规模、种类和数量迅速增加。数据集是当代NLP的一个社区图书馆,旨在支持这一生态系统。数据集旨在将终端用户界面、版本和文件标准化,同时为小型数据集提供一个与互联网规模公司相似的轻量级前端。图书馆的设计包含一种分散的、由社区驱动的方法来添加数据集和记录使用。经过一年的发展,图书馆现在包括650多个独特的数据集,有250多个用户,帮助支持各种新的交叉数据集研究项目和共同任务。图书馆可在https://github.com/huggface/dataset查阅。