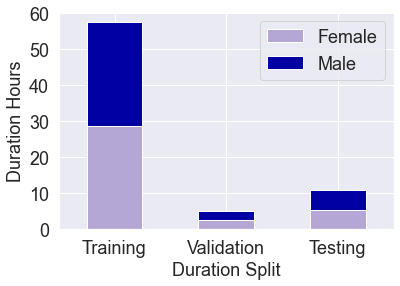
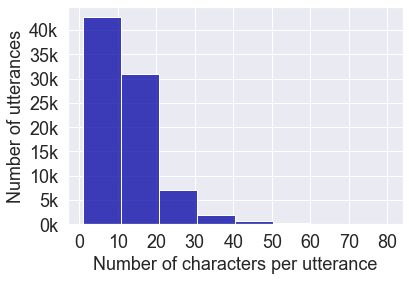
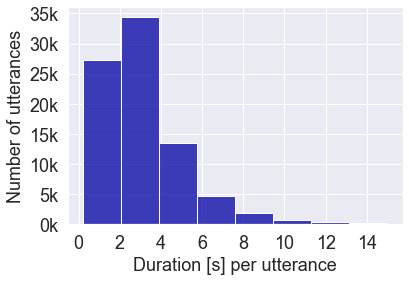
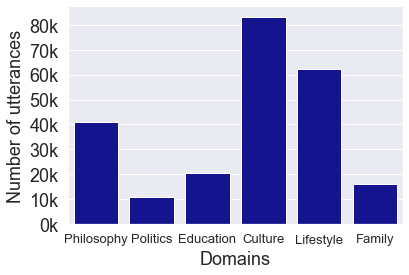
Automatic speech recognition (ASR) on low resource languages improves access of linguistic minorities to technological advantages provided by Artificial Intelligence (AI). In this paper, we address a problem of data scarcity of Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It combines philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and perform experiments on the two biggest datasets (MDCC and Common Voice zh-HK). We analyze the existing datasets according to their speech type, data source, total size and availability. The results of experiments conducted with Fairseq S2T Transformer, a state-of-the-art ASR model, show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
翻译:有关低资源语言的自动语音识别(ASR)提高了语言少数群体获得人工智能(AI)技术优势的机会。在本文中,我们通过创建一个新的广东数据集,解决了香港大陆语言数据稀缺的问题。我们的数据集,多域广东公司(MDCC),由73.6小时的清洁读话和来自香港的广东音频书收集的笔录组成。它结合了哲学、政治、教育、文化、生活方式和家庭领域,涵盖广泛的主题。我们还审查了所有现有的广东数据集,并对两个最大的数据集(MDCC和普通语音ZH-HK)进行了实验。我们根据这些数据集的语音类型、数据来源、总大小和可用性,对现有的数据集进行了分析。与Fairseq S2T变形器进行的实验结果显示了我们数据集的有效性。此外,我们通过在MCC和普通声频HK应用多数据集学习,创建了一个强大和强大的广东域的ASR模型。