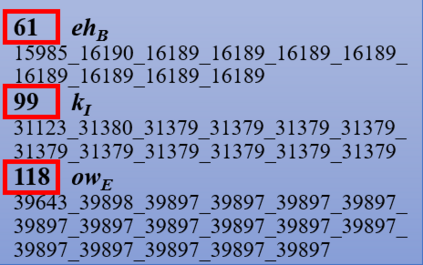
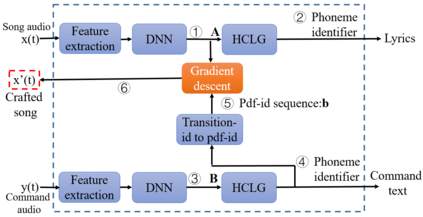
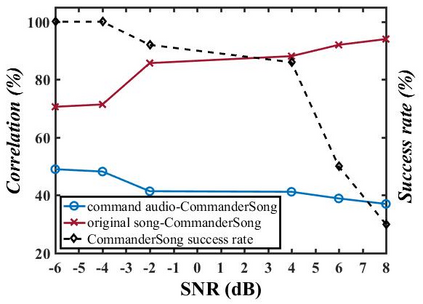
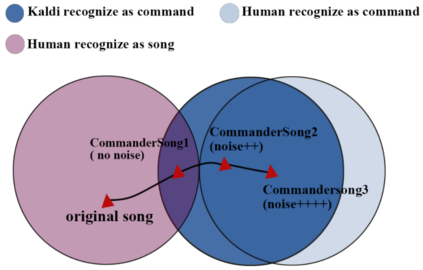
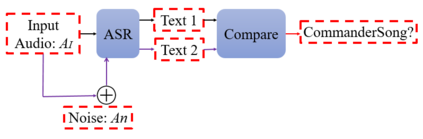
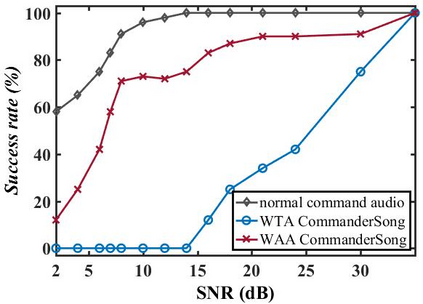
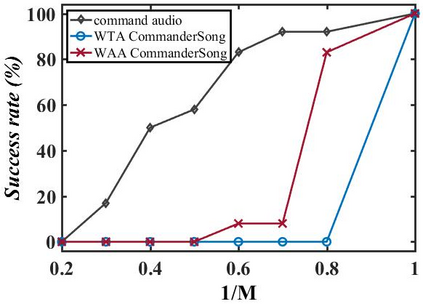
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.
翻译:谷歌之声、科尔塔纳等自动语音识别系统的普及(自动语音识别)系统,如最近袭击所显示的那样,带来了安全关切。然而,这种威胁的影响不那么明显,因为它们不是隐蔽(产生类似声音的语音指令),就是要求攻击装置(使用超声波)实际存在。在本文中,我们表明,不仅更实际和隐蔽的攻击是可行的,而且甚至可以自动构建。具体地说,我们发现声音指令可以隐蔽地嵌入歌曲中,一旦播放,可以通过ASR有效控制目标系统而不受注意。为此,我们开发了应对关键技术挑战的新技术:将指令纳入歌曲中,这种方式在有背景噪音的情况下可以被ASR有效地识别,但人类听众无法察觉。我们的研究显示,这可以自动针对现实世界的ASR应用程序进行。我们还表明,这些指挥Song可以通过互联网(例如YouTube)和电台传播,从而有可能影响数百万ASR用户。我们提出了新的缓解技术控制方法。