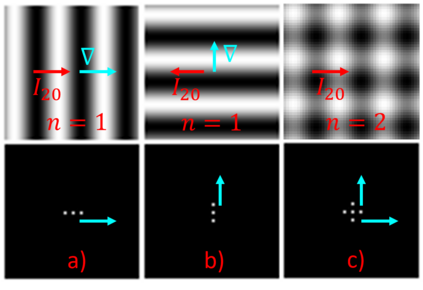
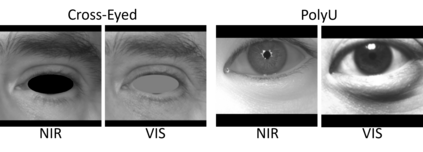
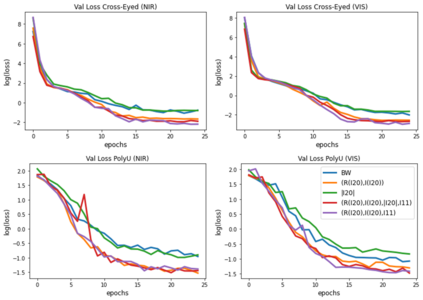
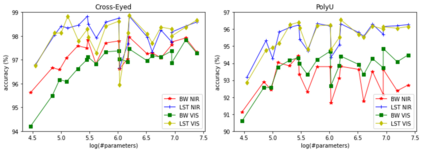
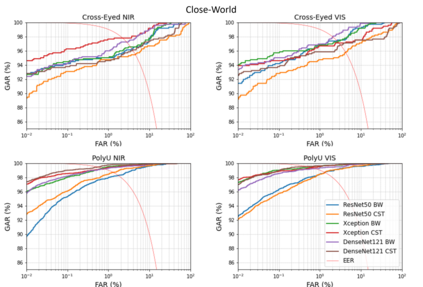
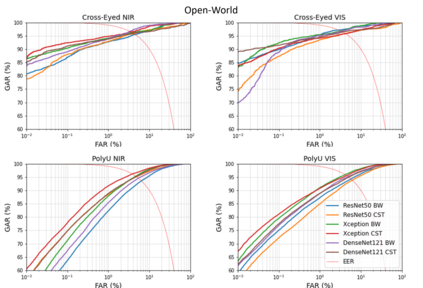
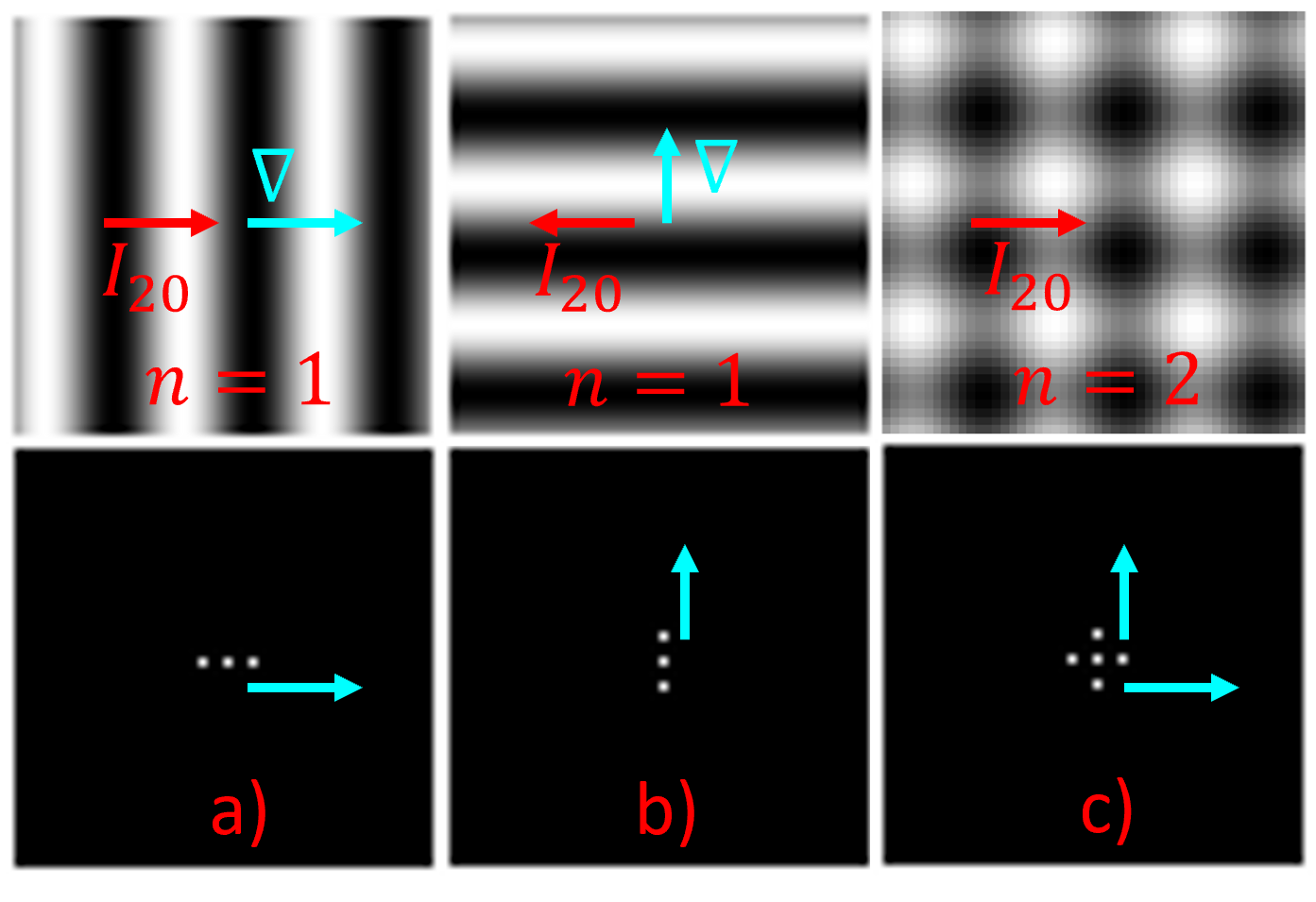
Our study provides evidence that CNNs struggle to effectively extract orientation features. We show that the use of Complex Structure Tensor, which contains compact orientation features with certainties, as input to CNNs consistently improves identification accuracy compared to using grayscale inputs alone. Experiments also demonstrated that our inputs, which were provided by mini complex conv-nets, combined with reduced CNN sizes, outperformed full-fledged, prevailing CNN architectures. This suggests that the upfront use of orientation features in CNNs, a strategy seen in mammalian vision, not only mitigates their limitations but also enhances their explainability and relevance to thin-clients. Experiments were done on publicly available data sets comprising periocular images for biometric identification and verification (Close and Open World) using 6 State of the Art CNN architectures. We reduced SOA Equal Error Rate (EER) on the PolyU dataset by 5-26% depending on data and scenario.
翻译:暂无翻译