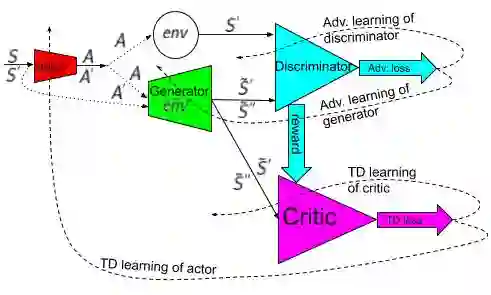
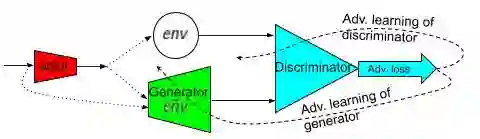
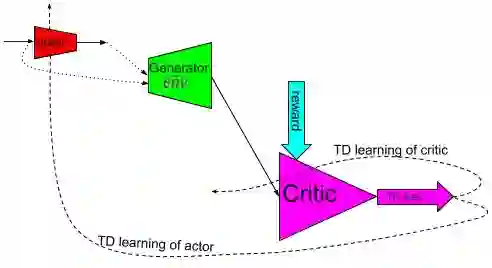
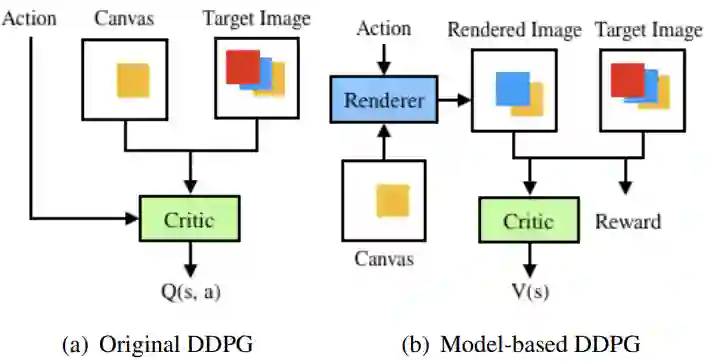
Our effort is toward unifying GAN and DRL algorithms into a unifying AI model (AGI or general-purpose AI or artificial general intelligence which has general-purpose applications to: (A) offline learning (of stored data) like GAN in (un/semi-/fully-)SL setting such as big data analytics (mining) and visualization; (B) online learning (of real or simulated devices) like DRL in RL setting (with/out environment reward) such as (real or simulated) robotics and control; Our core proposal is adding an (generative/predictive) environment model to the actor-critic (model-free) architecture which results in a model-based actor-critic architecture with temporal-differencing (TD) error and an episodic memory. The proposed AI model is similar to (model-free) DDPG and therefore it's called model-based DDPG. To evaluate it, we compare it with (model-free) DDPG by applying them both to a variety (wide range) of independent simulated robotic and control task environments in OpenAI Gym and Unity Agents. Our initial limited experiments show that DRL and GAN in model-based actor-critic results in an incremental goal-driven intellignce required to solve each task with similar performance to (model-free) DDPG. Our future focus is to investigate the proposed AI model potential to: (A) unify DRL field inside AI by producing competitive performance compared to the best of model-based (PlaNet) and model-free (D4PG) approaches; (B) bridge the gap between AI and robotics communities by solving the important problem of reward engineering with learning the reward function by demonstration.
翻译:我们的努力是将GAN和DRL算法统一为一个统一的AI模型(AGI或通用AI或通用AI或人工通用智能),这种模型具有一般用途应用:(A)在(un/semi-/frim-)SL设置中,像GAN那样的离线学习(储存数据),在(un/semi-/frim-)SL设置中,例如大数据分析器(采矿)和直观化;(B)在RL设置中(有/有/有)DRL(有/有)实际或模拟的DRL算法(有/有/没有环境奖赏),例如(有/没有环境奖赏)的机器人和控制工具;我们的核心建议是在(没有模型的)演员-cregal-critic(没有模型)结构中,在(没有模型的)在(没有模型的)Ormal-IAAA(没有模型)中,在Ormal-L ADR(有(没有)A-I-I-I-I-I-IL任务运行中,显示A-IL-IL-IL-I-I-I-I-I-I-I-I-I-I-I-IL-IL-IL-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-IL-I-I-I-I-I-I-IL-I-IL-IL-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-