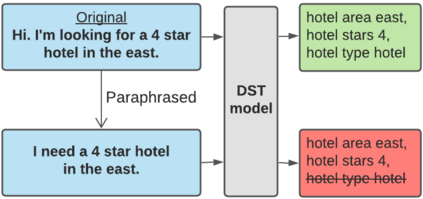
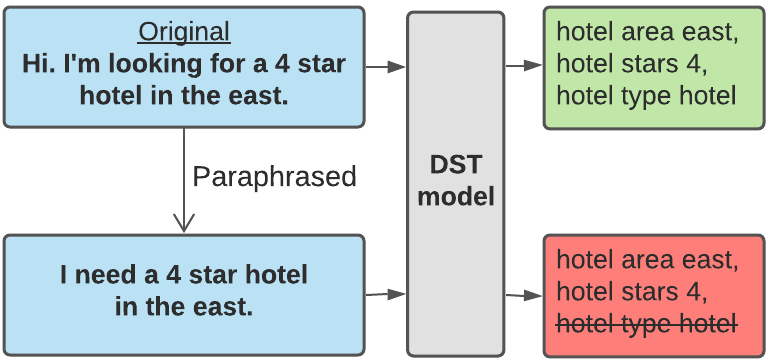
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
翻译:将前列-当时-菲内特模式扩展出去的近期神经模型继续在对话国家跟踪(DST)基准的联合目标准确性(JGA)方面实现新的最新最新成果。然而,我们质疑这些模型的稳健性,因为它们显示JGA在包含发声或对话流的交谈中以现实的扰动方式出现急剧下降。我们发现,基于区域分类模型的适应性强于未知实体,但并不强于语言多样性,而基于自动偏重语言模型的分类模型则比较优于语言多样性,但倾向于以强化测试器测试已知的弱点来比较被点名的实体,并往往产生幻觉。我们评估最近与CryDST公司(CryDST)合作的DST模型,并争论说,由于这些模型的弱点,应当更全面地评估,而不是在JGA公司上追求状态,因为更高的JGAGA公司并不能保证更好的总体稳健性。我们发现,基于区域分类模型的模型对未知的命名实体具有弹性,但对语言多样性并不强,而基于自动偏重语言模型的模型的模型则更宽泛,但往往对被点化的被点名实体和往往具有幻想性。由于各自的弱点,因此,对于未来对话的模型都不适宜于真实性。