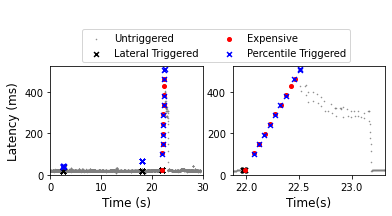
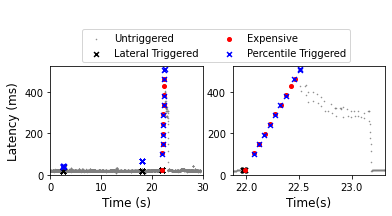
Today's distributed tracing frameworks only trace a small fraction of all requests. For application developers troubleshooting rare edge-cases, the tracing framework is unlikely to capture a relevant trace at all, because it cannot know which requests will be problematic until after-the-fact. Application developers thus heavily depend on luck. In this paper, we remove the dependence on luck for any edge-case where symptoms can be programmatically detected, such as high tail latency, errors, and bottlenecked queues. We propose a lightweight and always-on distributed tracing system, Hindsight, where each constituent node acts analogously to a car dash-cam that, upon detecting a sudden jolt in momentum, persists the last hour of footage. Hindsight implements a retroactive sampling abstraction: when the symptoms of a problem are detected, Hindsight retrieves and persists coherent trace data from all relevant nodes that serviced the request. Developers using Hindsight receive the exact edge-case traces they desire; by comparison existing sampling-based tracing systems depend wholly on serendipity. Our experimental evaluation shows that Hindsight successfully collects edge-case symptomatic requests in real-world use cases. Hindsight adds only nanosecond-level overhead to generate trace data, can handle GB/s of data per node, transparently integrates with existing distributed tracing systems, and persists full, detailed traces when an edge-case problem is detected.
翻译:今天分布式追踪框架只追溯到所有请求中的一小部分。 对于排除稀有边框的应用程序开发者来说,追踪框架不可能完全捕捉到相关的线索, 因为它在事后无法知道哪些请求会有问题。 应用程序开发者因此在很大程度上依赖于运气。 在本文中, 我们不再依赖任何边框的运气, 在边框中, 可以通过程序检测出症状, 例如高尾悬浮、 错误和瓶颈的队列。 我们建议一个轻量且总是在边框分布式追踪系统 Hindsight, 每一个组件的节点都类似于一个汽车破碎摄像头, 因为它在发现突然的摇摆动后, 无法了解最后一小时的画面。 应用程序视图将执行追溯性抽样抽取: 当发现问题的症状时, Hindsight 检索并持续从所有符合请求的所有相关节点( 如高尾悬浮、 错误和瓶颈队列队列队列) 开发者会收到他们想要的准确的边框跟踪; 比较现有的基于取样的追踪系统, 完全取决于时间。 我们的实验性评估显示, 光谱- 光谱- 正在成功地收集真实的轨迹定的轨道, 每一个轨道处理 。