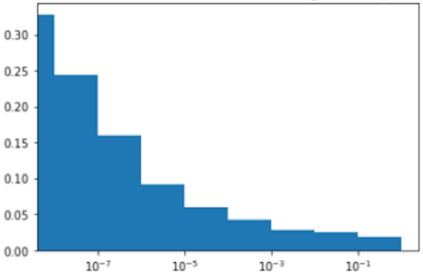
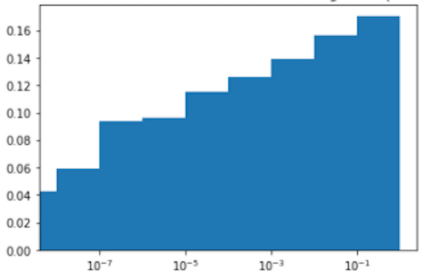
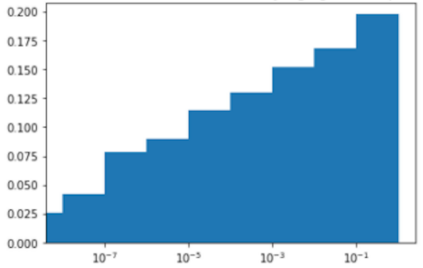
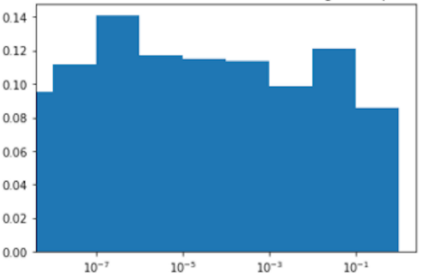
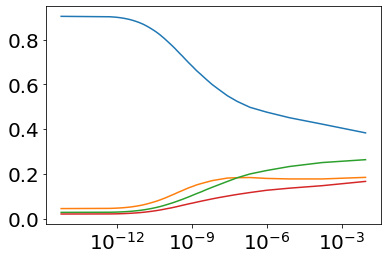
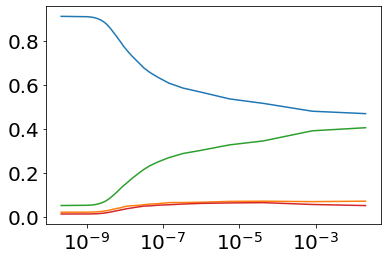
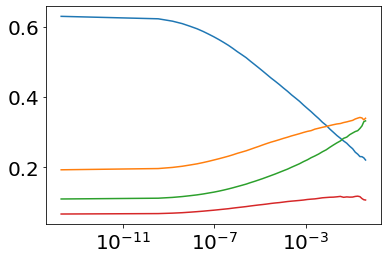
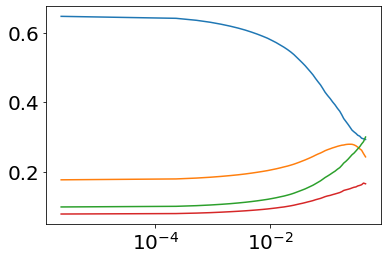
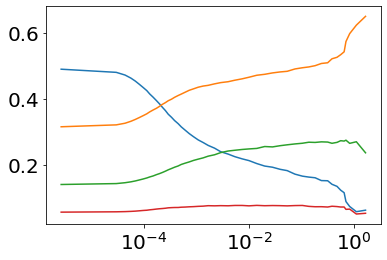
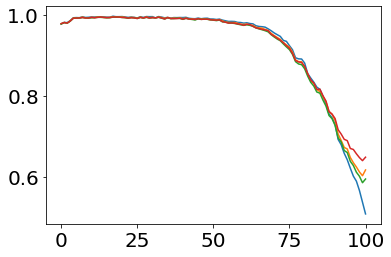
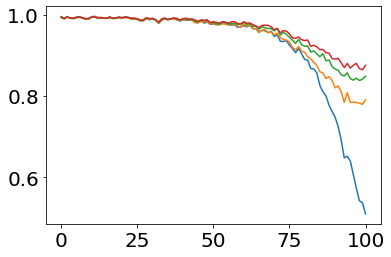
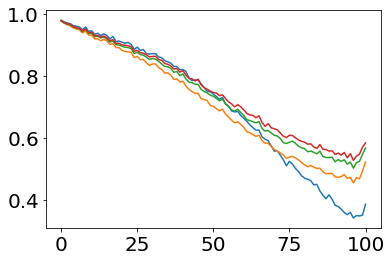
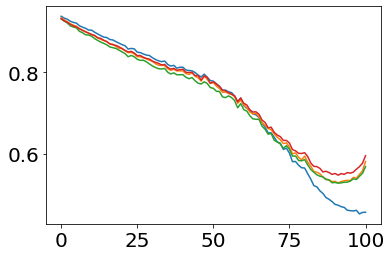
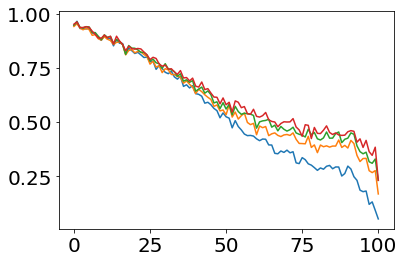
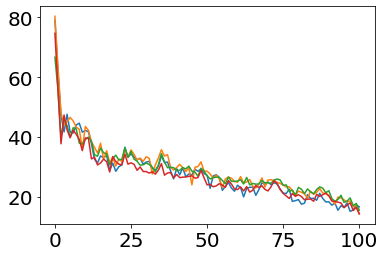
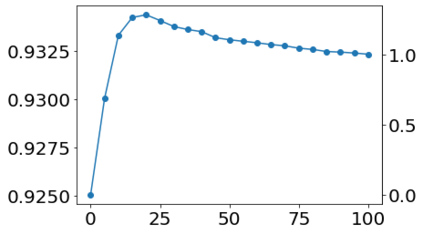
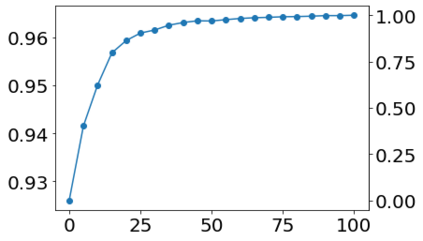
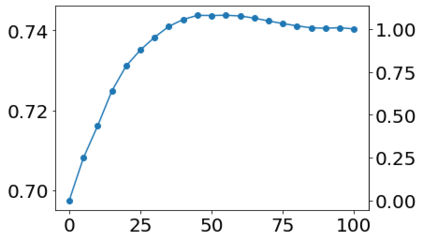
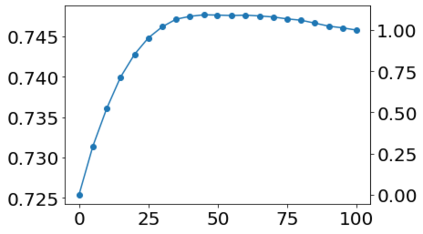
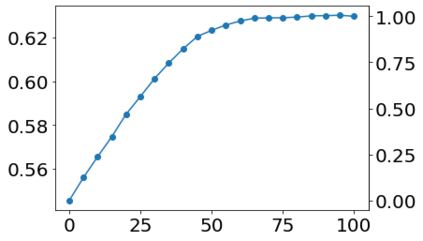
Much effort has been devoted to making large and more accurate models, but relatively little has been put into understanding which examples are benefiting from the added complexity. In this paper, we demonstrate and analyze the surprisingly tight link between a model's predictive uncertainty on individual examples and the likelihood that larger models will improve prediction on them. Through extensive numerical studies on the T5 encoder-decoder architecture, we show that large models have the largest improvement on examples where the small model is most uncertain. On more certain examples, even those where the small model is not particularly accurate, large models are often unable to improve at all, and can even perform worse than the smaller model. Based on these findings, we show that a switcher model which defers examples to a larger model when a small model is uncertain can achieve striking improvements in performance and resource usage. We also explore committee-based uncertainty metrics that can be more effective but less practical.
翻译:已经为制作大型和更为准确的模型做出了很大的努力,但相对而言,对于哪些实例从增加的复杂性中受益的理解却很少。在本文件中,我们展示和分析了模型单个实例的预测不确定性与较大模型改进预测的可能性之间的令人惊讶的紧密联系。我们通过对T5编码器脱coder-decoder结构的广泛数字研究,表明大型模型在小型模型最不确定的示例方面有最大的改进。在更某些实例中,即使小型模型不特别准确,大型模型往往根本无法改进,甚至能够比小型模型更差。根据这些调查结果,我们表明,在小型模型不确定的情况下,将实例放入更大模型的开关模型,可以在性能和资源使用方面实现显著的改进。我们还探讨了基于委员会的不确定性指标,这些指标可能更加有效,但不太实用。