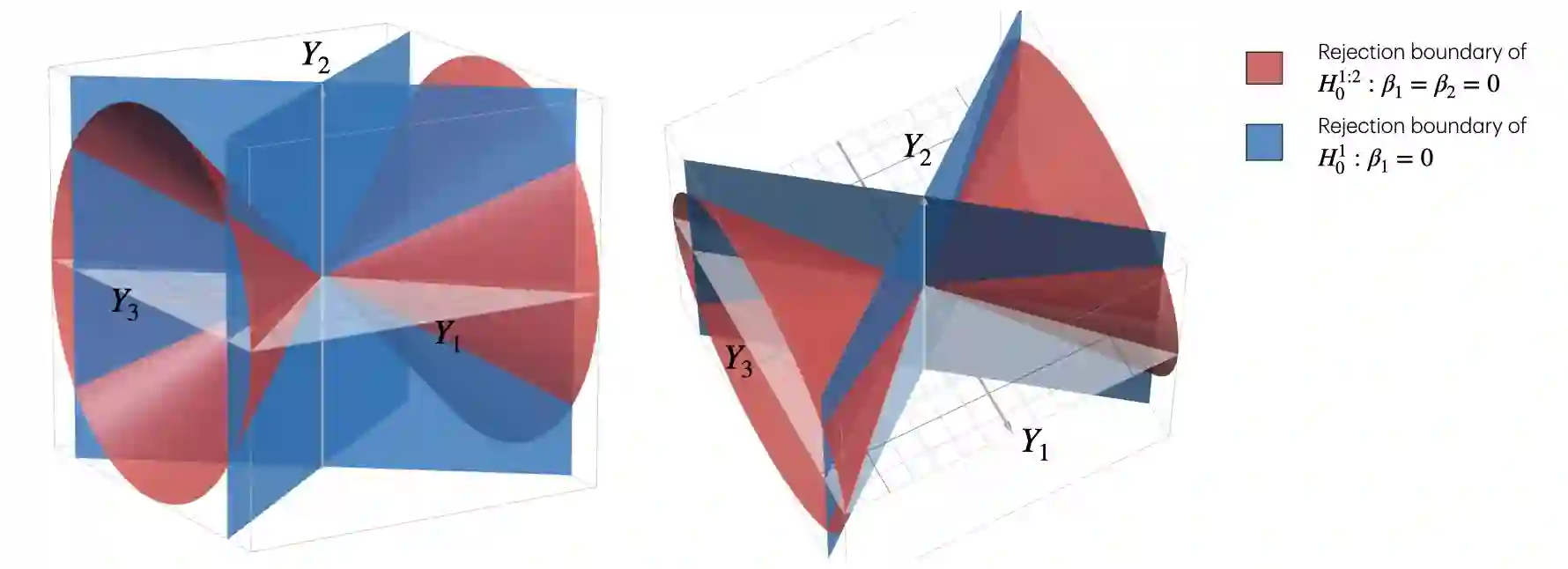
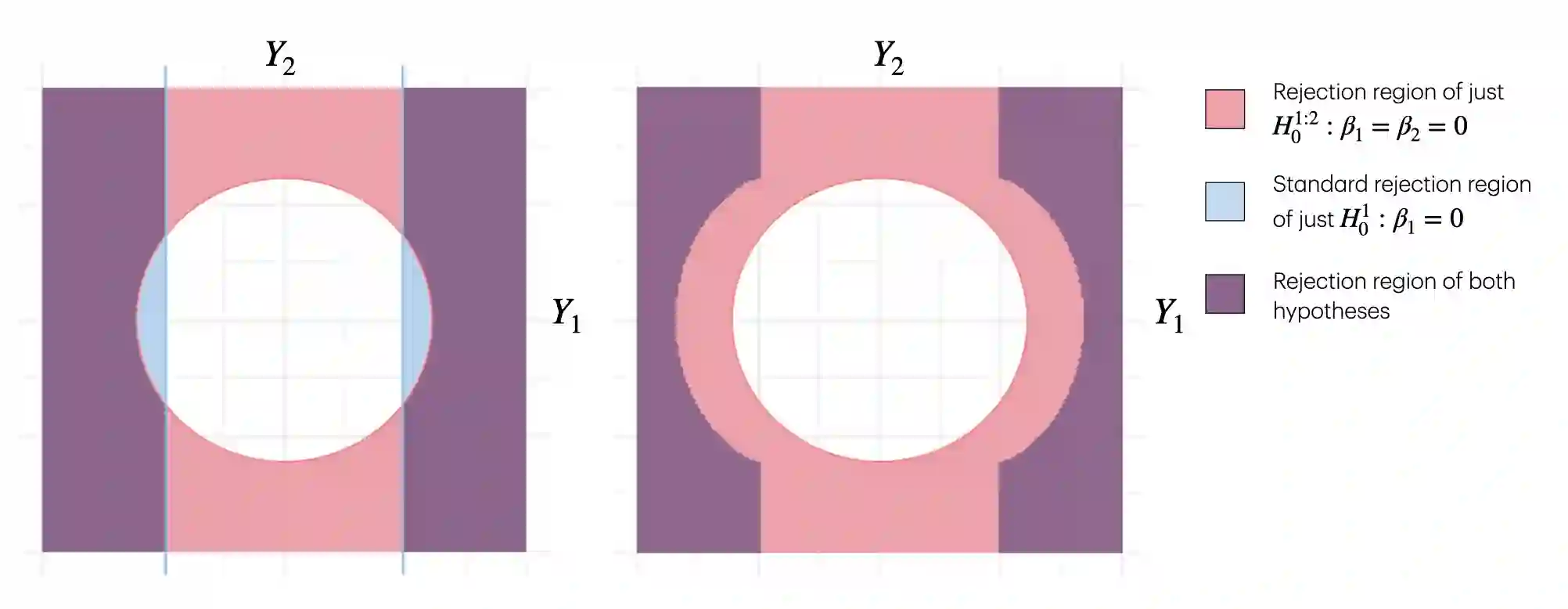
Suppose that a data analyst wishes to report the results of a least squares linear regression only if the overall null hypothesis, $H_0^{1:p}: \beta_1= \beta_2 = \ldots = \beta_p=0$, is rejected. This practice, which we refer to as F-screening (since the overall null hypothesis is typically tested using an $F$-statistic), is in fact common practice across a number of applied fields. Unfortunately, it poses a problem: standard guarantees for the inferential outputs of linear regression, such as Type 1 error control of hypothesis tests and nominal coverage of confidence intervals, hold unconditionally, but fail to hold conditional on rejection of the overall null hypothesis. In this paper, we develop an inferential toolbox for the coefficients in a least squares model that are valid conditional on rejection of the overall null hypothesis. We develop selective p-values that lead to tests that are consistent and control the selective Type 1 error, i.e., the Type 1 error conditional on having rejected the overall null hypothesis. Furthermore, they can be computed without access to the raw data, i.e., using only the standard outputs of a least squares linear regression, and therefore are suitable for use in a retrospective analysis of a published study. We also develop confidence intervals that attain nominal selective coverage, and point estimates that account for having rejected the overall null hypothesis. We derive an expression for the Fisher information about the coefficients resulting from the proposed approach, and compare this to the Fisher information that results from an alternative approach that relies on sample splitting. We investigate the proposed approach in simulation and via re-analysis of two datasets from the biomedical literature.
翻译:假设数据分析师仅当整体零假设 $H_0^{1:p}: \beta_1= \beta_2 = \ldots = \beta_p=0$ 被拒绝时,才报告最小二乘线性回归的结果。这种实践(我们称之为F筛选,因为整体零假设通常使用$F$统计量进行检验)在多个应用领域中实际上是常见做法。然而,这带来了一个问题:线性回归推断输出的标准保证(如假设检验的I类错误控制和置信区间的名义覆盖率)是无条件成立的,但在整体零假设被拒绝的条件下不再成立。本文针对最小二乘模型中的系数,开发了一套在整体零假设被拒绝条件下有效的推断工具。我们提出了选择性p值,这些p值产生的检验具有一致性,并能控制选择性I类错误(即在整体零假设被拒绝条件下的I类错误)。此外,这些p值无需访问原始数据即可计算(仅需最小二乘线性回归的标准输出),因此适用于对已发表研究进行回顾性分析。我们还开发了达到名义选择性覆盖率的置信区间,以及考虑了整体零假设被拒绝情况的点估计。我们推导了所提方法产生的系数Fisher信息表达式,并将其与依赖样本分割的替代方法产生的Fisher信息进行比较。我们通过模拟和重新分析生物医学文献中的两个数据集,对所提方法进行了研究。