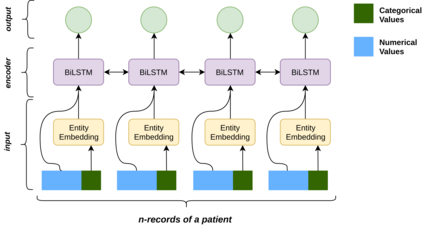
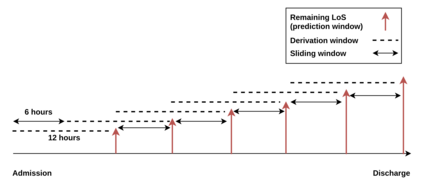
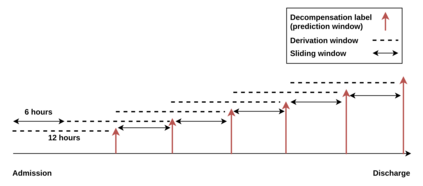
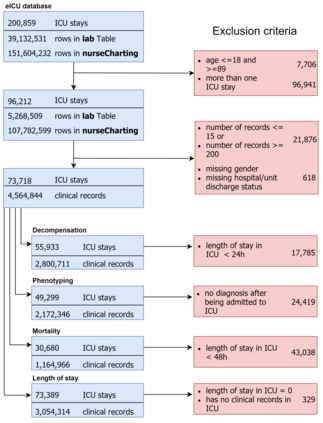
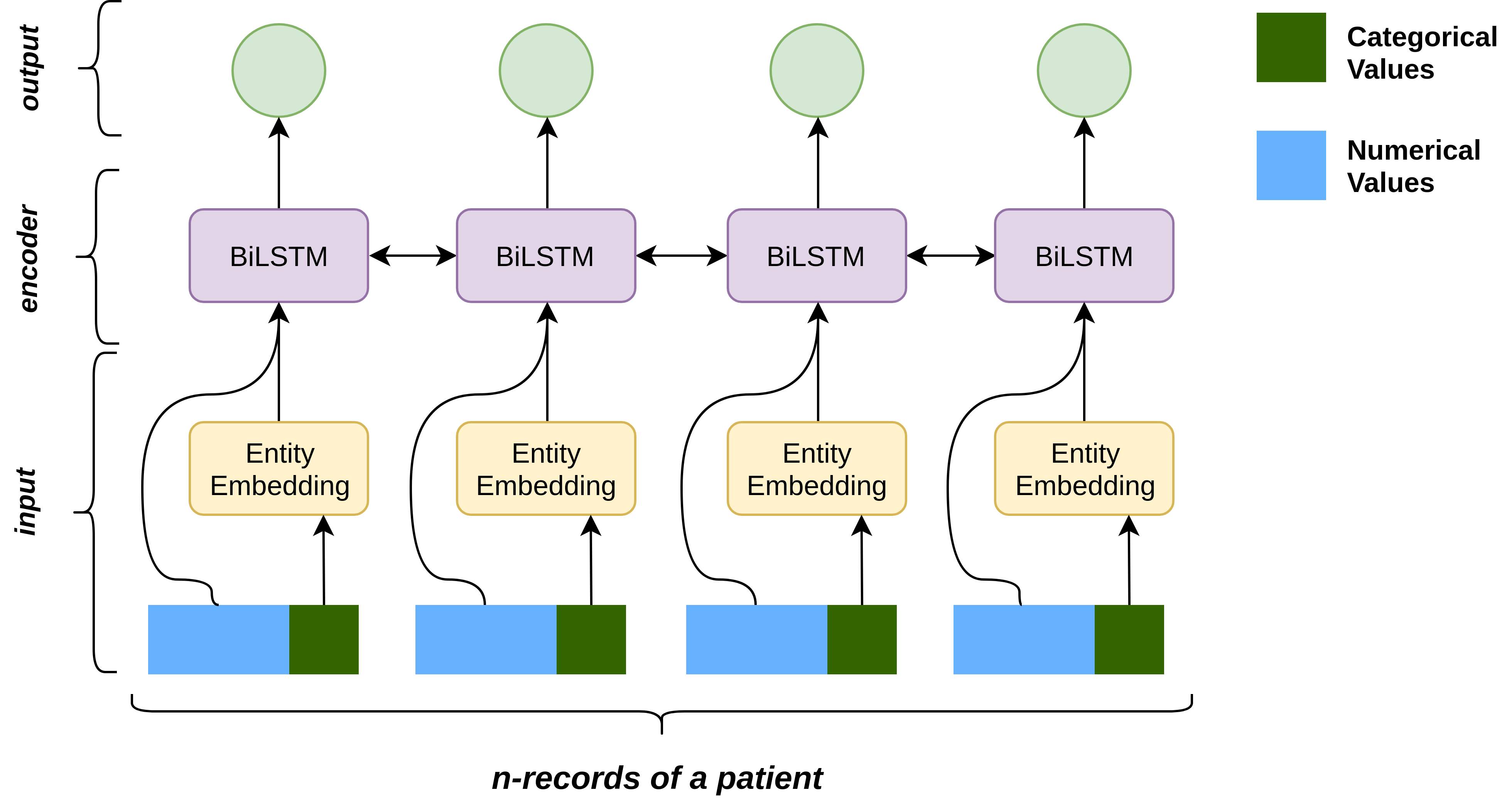
Progress of machine learning in critical care has been difficult to track, in part due to absence of public benchmarks. Other fields of research (such as computer vision and natural language processing) have established various competitions and public benchmarks. Recent availability of large clinical datasets has enabled the possibility of establishing public benchmarks. Taking advantage of this opportunity, we propose a public benchmark suite to address four areas of critical care, namely mortality prediction, estimation of length of stay, patient phenotyping and risk of decompensation. We define each task and compare the performance of both clinical models as well as baseline and deep learning models using eICU critical care dataset of around 73,000 patients. This is the first public benchmark on a multi-centre critical care dataset, comparing the performance of clinical gold standard with our predictive model. We also investigate the impact of numerical variables as well as handling of categorical variables on each of the defined tasks. The source code, detailing our methods and experiments is publicly available such that anyone can replicate our results and build upon our work.
翻译:关键护理的机器学习进展一直难以追踪,部分原因是缺乏公共基准,其他研究领域(如计算机视觉和自然语言处理)已经建立了各种竞争和公共基准,最近提供的大型临床数据集使得有可能建立公共基准。利用这一机会,我们提出一个公共基准套件,以处理四个关键护理领域,即死亡率预测、估计停留时间、病人口腔和赔偿风险。我们界定了每项任务,并比较临床模型以及基线和深层次学习模型的绩效,使用电子疾病分类系统关键护理数据集对大约73 000名病人进行了比较。这是多中心关键护理数据集的第一个公共基准,将临床黄金标准的业绩与我们的预测模型进行比较。我们还调查数字变量的影响,以及处理对每项既定任务绝对变量的影响。源代码详细介绍了我们的方法和实验,可供公众查阅,以便任何人都可以复制我们的成果,并以我们的工作为基础。