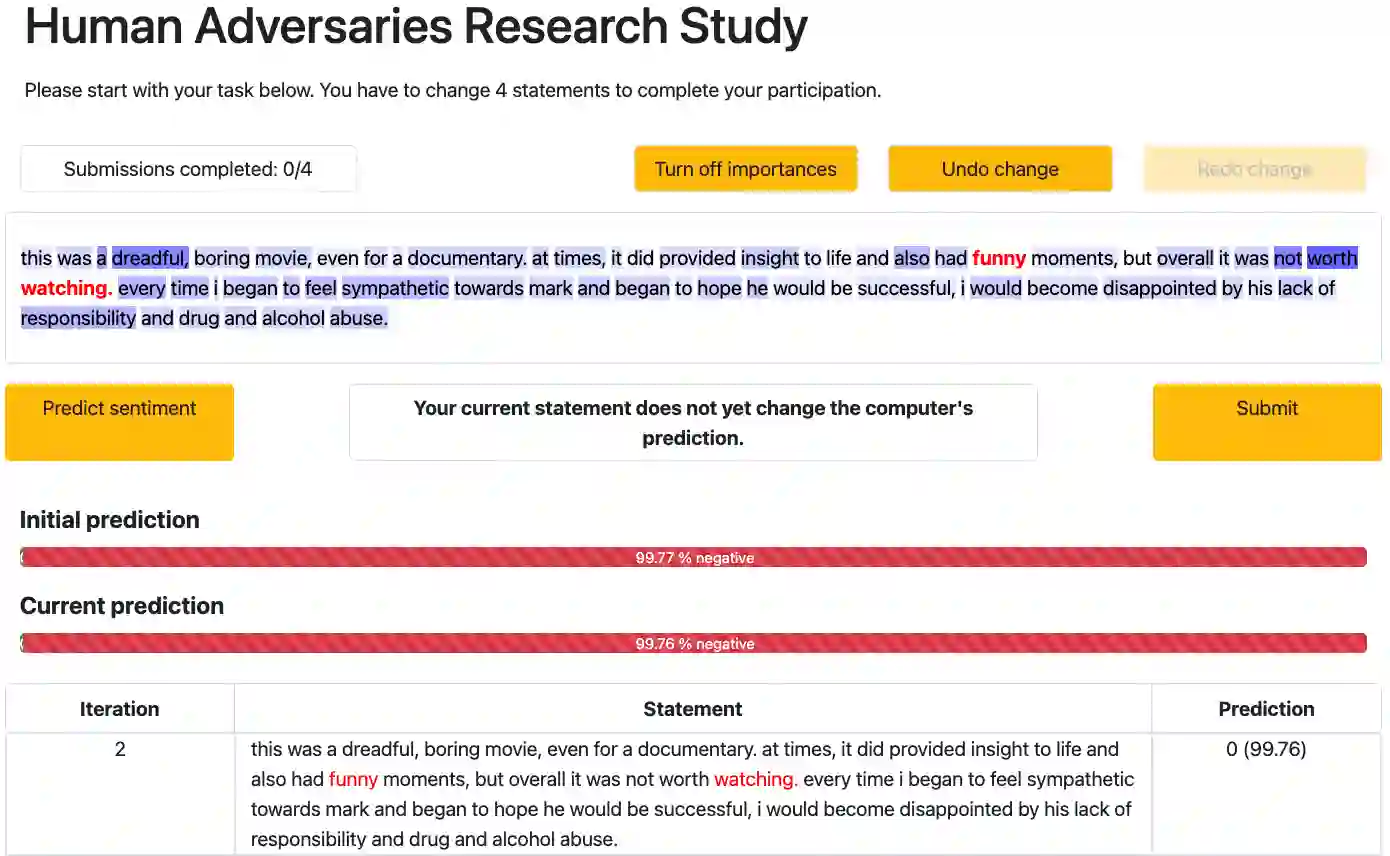
Research shows that natural language processing models are generally considered to be vulnerable to adversarial attacks; but recent work has drawn attention to the issue of validating these adversarial inputs against certain criteria (e.g., the preservation of semantics and grammaticality). Enforcing constraints to uphold such criteria may render attacks unsuccessful, raising the question of whether valid attacks are actually feasible. In this work, we investigate this through the lens of human language ability. We report on crowdsourcing studies in which we task humans with iteratively modifying words in an input text, while receiving immediate model feedback, with the aim of causing a sentiment classification model to misclassify the example. Our findings suggest that humans are capable of generating a substantial amount of adversarial examples using semantics-preserving word substitutions. We analyze how human-generated adversarial examples compare to the recently proposed TextFooler, Genetic, BAE and SememePSO attack algorithms on the dimensions naturalness, preservation of sentiment, grammaticality and substitution rate. Our findings suggest that human-generated adversarial examples are not more able than the best algorithms to generate natural-reading, sentiment-preserving examples, though they do so by being much more computationally efficient.
翻译:研究显示,自然语言处理模式通常被认为容易受到对抗性攻击;但最近的工作提请注意根据某些标准(例如,保留语义和语法学)验证这些对抗性投入的问题。 坚持这些标准的制约可能会使攻击不成功,从而提出有效攻击是否实际可行的问题。 在这项工作中,我们从人类语言能力的角度来调查这一问题。我们报告了众包研究,在这种研究中,我们要求人类在输入文本中用迭代修改词,同时收到即时的模型反馈,目的是造成情绪分类模型错误分类。我们的调查结果表明,人类能够利用语义保留词替换生成大量对抗性例子。我们分析了人类产生的对抗性例子如何与最近提议的TextFooler、遗传学、BAE和SemePSO攻击算法相比较,其范围是自然特性、情绪保存、重感光度和替换率。我们的研究结果表明,人类产生的对抗性例子并不比最佳的算法更有能力产生大量的对抗性计算方法,但通过如此高效的计算来保存感知力。