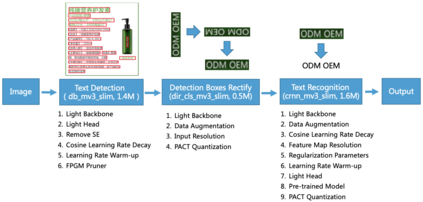
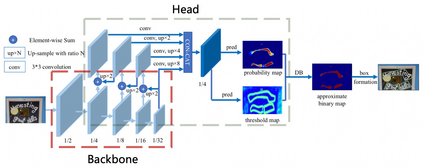
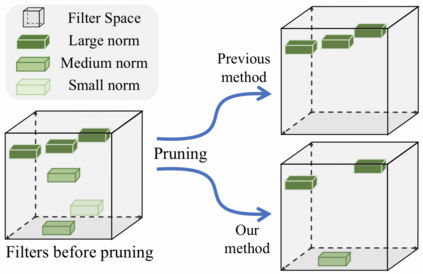
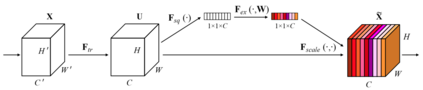
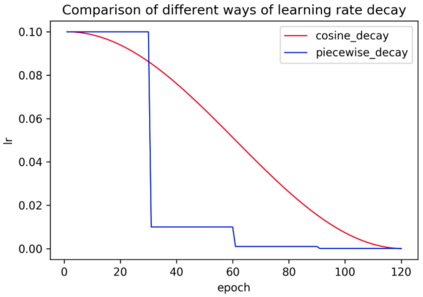
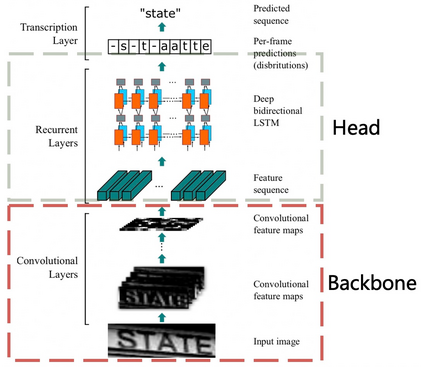
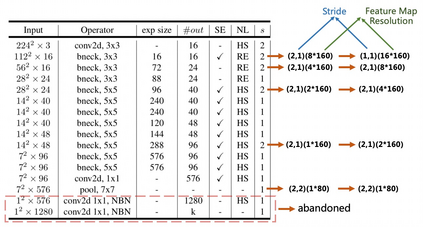
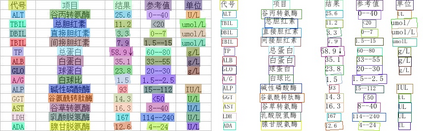
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.
翻译:光性特征识别系统(OCR)在各种应用情景中被广泛使用,例如办公室自动化系统、工厂自动化、在线教育、地图制作等。然而,光性特征识别系统由于各种文本外观和计算效率的需求,仍是一项艰巨的任务。在本文件中,我们建议采用实用的超轻度光性OCR系统,即PP-OCR。P-OCR的总体模型规模仅为3.5M,用于识别6622个中国字符,28M,用于识别63个字母数字符号。我们引入了一包战略,既可以增强模型能力,也可以缩小模型大小。我们还提供了与真实数据相应的缩缩缩缩实验。与此同时,还发布了一些经过预先培训的中英中文识别模型,包括文本检测器(使用97K图像)、方向分类器(使用600K图像)以及文本识别器(使用17.9M图像)。此外,还核实了拟议的PPP-OCR。此外,还在包括法文、韩文、日文和德文在内的多种语言识别任务中文本/德文中文本库中,所有上述的GIPR/drbs。