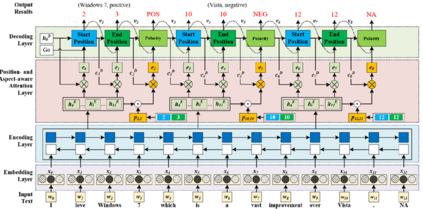
Extracting aspect-polarity pairs from texts is an important task of fine-grained sentiment analysis. While the existing approaches to this task have gained many progresses, they are limited at capturing relationships among aspect-polarity pairs in a text, thus degrading the extraction performance. Moreover, the existing state-of-the-art approaches, namely token-based se-quence tagging and span-based classification, have their own defects such as polarity inconsistency resulted from separately tagging tokens in the former and the heterogeneous categorization in the latter where aspect-related and polarity-related labels are mixed. In order to remedy the above defects, in-spiring from the recent advancements in relation extraction, we propose to generate aspect-polarity pairs directly from a text with relation extraction technology, regarding aspect-pairs as unary relations where aspects are enti-ties and the corresponding polarities are relations. Based on the perspective, we present a position- and aspect-aware sequence2sequence model for joint extraction of aspect-polarity pairs. The model is characterized with its ability to capture not only relationships among aspect-polarity pairs in a text through the sequence decoding, but also correlations between an aspect and its polarity through the position- and aspect-aware attentions. The experi-ments performed on three benchmark datasets demonstrate that our model outperforms the existing state-of-the-art approaches, making significant im-provement over them.
翻译:从文本中抽取分极性对等,是细微情绪分析的重要任务。虽然目前对这项任务采取的办法取得了许多进展,但它们在从文本中捕捉分极性对等之间的关系方面受到限制,从而降低了抽取绩效。此外,现有最先进的办法,即基于象征性的内分泌标记和基于跨边界的分类,本身的缺陷,如在文本中分别标记标记符号和在文本中不同分类导致极性不一致,在后者中,与方面相关的和与极性有关的标签混杂在一起。为了纠正上述缺陷,我们建议直接从与采掘技术有关的案文中产生分极性对等关系,在文本中将方对等关系作为单性关系,在内容是内分异性的内分极性标记和对立关系。从这个角度出发,我们为共同提取分极性对等标签的定位和分异性分类,其特征是,不仅能够从近期的提取关系中汲取上述缺陷,我们还提议从与采掘技术有关的文本中直接产生分极性对等关系,而且还通过正级数据显示其正对等关系。