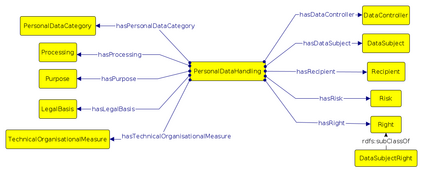
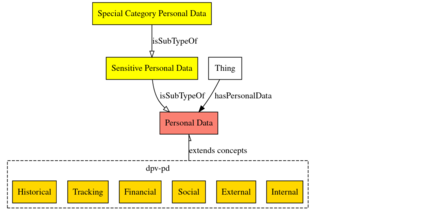
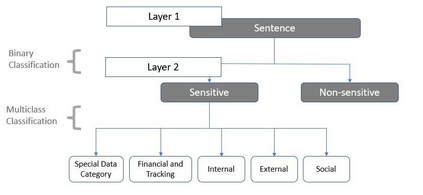
In recent years we have seen the exponential growth of applications, including dialogue systems, that handle sensitive personal information. This has brought to light the extremely important issue regarding personal data protection in virtual environments. Firstly, a performing model should be able to distinguish sentences with sensitive content from neutral sentences. Secondly, it should be able to identify the type of personal data category contained in them. In this way, a different privacy treatment could be considered for each category. In literature, if there are works on automatic sensitive data identification, these are often conducted on different domains or languages without a common benchmark. To fill this gap, in this work we introduce SPeDaC, a new annotated benchmark for the identification of sensitive personal data categories. Furthermore, we provide an extensive evaluation of our dataset, conducted using different baselines and a classifier based on RoBERTa, a neural architecture that achieves strong performances on the detection of sensitive sentences and on the personal data categories classification.
翻译:近年来,我们看到处理敏感个人信息的应用程序(包括对话系统)的指数增长,处理敏感个人信息的应用程序(包括对话系统)迅速增长,这揭示了虚拟环境中个人数据保护的极其重要的问题。首先,业绩模型应该能够区分敏感内容的句子和中性句子。第二,它应该能够识别其中的个人数据类别类型。这样,可以考虑对每一类别进行不同的隐私处理。在文献中,如果进行了自动敏感数据识别工作,这些往往在不同的领域或语言上进行,没有共同基准。为了填补这一空白,我们在这项工作中引入了SPeDaC,这是识别敏感个人数据类别的新附加说明的基准。此外,我们还利用不同基线和基于RoBERTA的分类器对我们的数据集进行了广泛的评估,该分类器是一个神经结构,在敏感判决的探测和个人数据分类方面表现强劲。