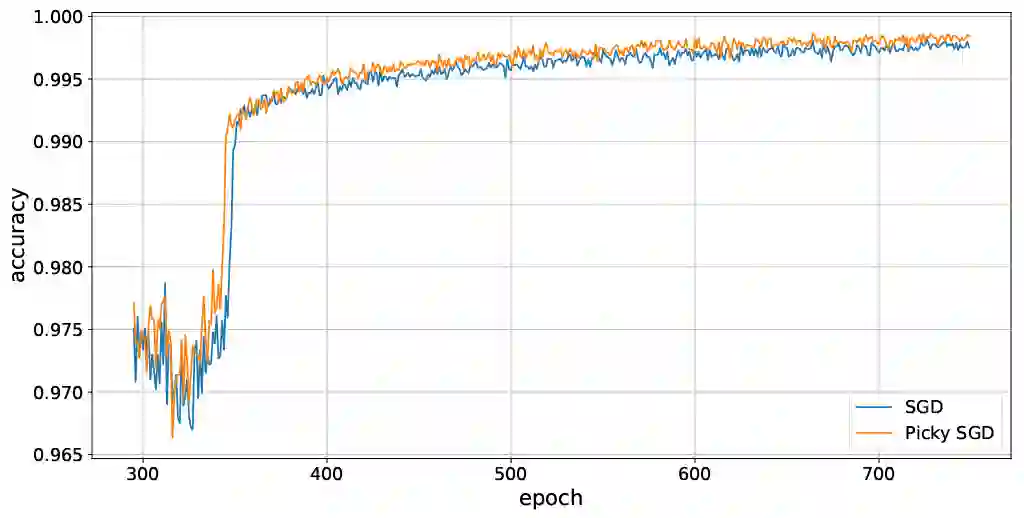
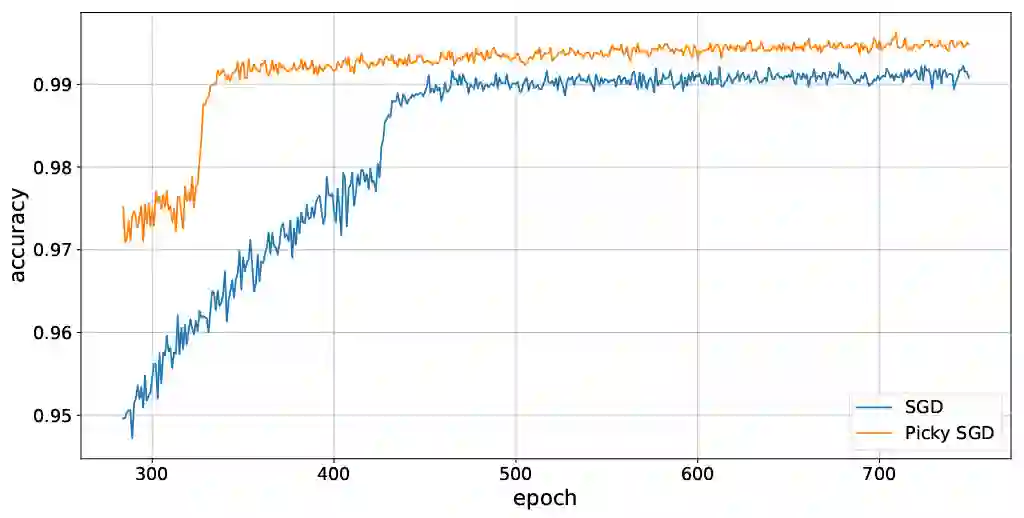
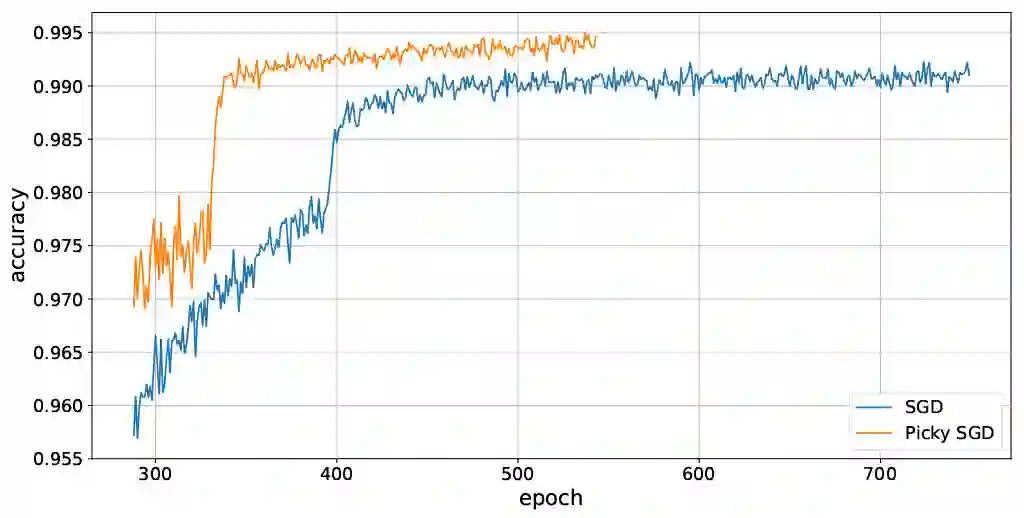
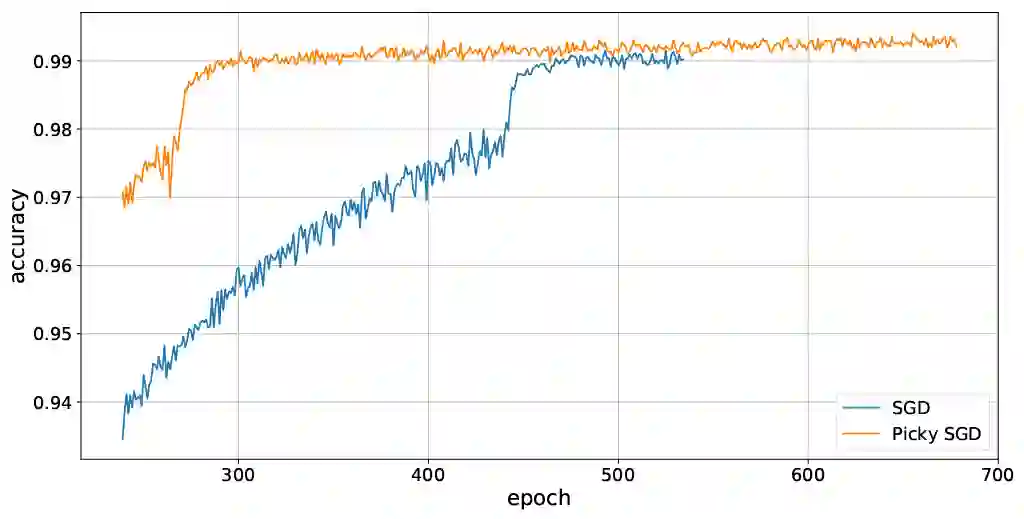
We consider stochastic optimization with delayed gradients where, at each time step $t$, the algorithm makes an update using a stale stochastic gradient from step $t - d_t$ for some arbitrary delay $d_t$. This setting abstracts asynchronous distributed optimization where a central server receives gradient updates computed by worker machines. These machines can experience computation and communication loads that might vary significantly over time. In the general non-convex smooth optimization setting, we give a simple and efficient algorithm that requires $O( \sigma^2/\epsilon^4 + \tau/\epsilon^2 )$ steps for finding an $\epsilon$-stationary point $x$, where $\tau$ is the \emph{average} delay $\smash{\frac{1}{T}\sum_{t=1}^T d_t}$ and $\sigma^2$ is the variance of the stochastic gradients. This improves over previous work, which showed that stochastic gradient decent achieves the same rate but with respect to the \emph{maximal} delay $\max_{t} d_t$, that can be significantly larger than the average delay especially in heterogeneous distributed systems. Our experiments demonstrate the efficacy and robustness of our algorithm in cases where the delay distribution is skewed or heavy-tailed.
翻译:我们用延迟的梯度来考虑使用延迟的梯度的随机优化, 每当每一步$t美元时, 算法都使用从阶梯$t - d_t$ 来进行更新, 从阶梯为$t - d_t$ 任意延迟 $_t$ 。 这设置了当中央服务器收到由工人机器计算的梯度更新时的抽象分布优化摘要。 这些机器可以经历可能随时间而变化的计算和通信负荷。 在一般的非康氏平滑优化设置中, 我们给出一个简单有效的算法, 需要从阶梯 $( \ sigma_ 2/\ epsilon4 +\ tau/\ epsilon_ 2 + $ tal_ d_ t$ t_ t_ t_ t_ tall_ t$) 来进行更新。 这改进了以往的工作, 这表明, 固定基梯度的固定点点 $- 美元 点点 美元- 美元 值的延迟率 能够显著地显示我们平均的基数 的基数 值 的分布率 。