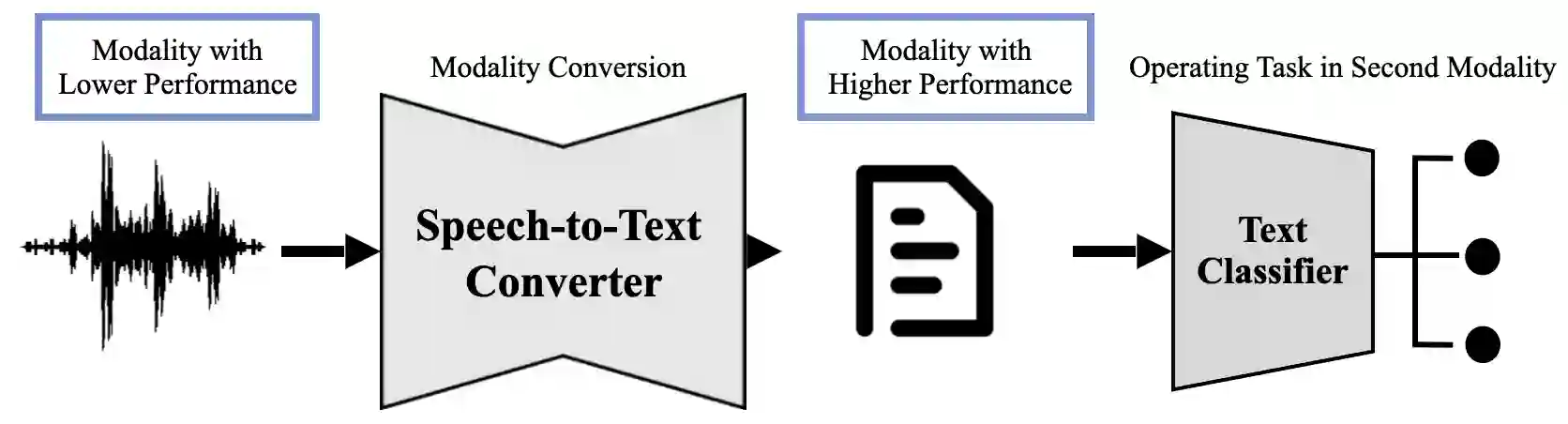
Speech Emotion Recognition (SER) is a challenging task. In this paper, we introduce a modality conversion concept aimed at enhancing emotion recognition performance on the MELD dataset. We assess our approach through two experiments: first, a method named Modality-Conversion that employs automatic speech recognition (ASR) systems, followed by a text classifier; second, we assume perfect ASR output and investigate the impact of modality conversion on SER, this method is called Modality-Conversion++. Our findings indicate that the first method yields substantial results, while the second method outperforms state-of-the-art (SOTA) speech-based approaches in terms of SER weighted-F1 (WF1) score on the MELD dataset. This research highlights the potential of modality conversion for tasks that can be conducted in alternative modalities.
翻译:暂无翻译