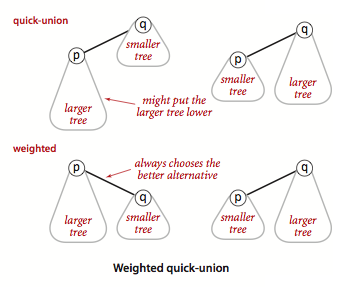
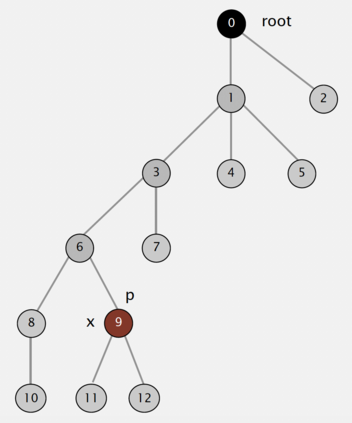
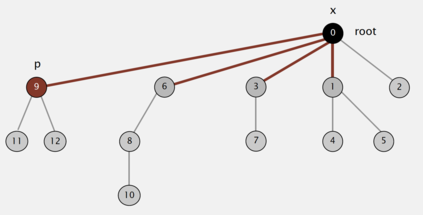
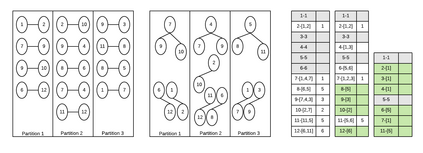
Large scale graph processing using distributed computing frameworks is becoming pervasive and efficient in the industry. In this work, we present a highly scalable and configurable distributed algorithm for building connected components, called Union Find Shuffle (UFS) with Path Compression. The scale and complexity of the algorithm are a function of the number of partitions into which the data is initially partitioned, and the size of the connected components. We discuss the complexity and the benchmarks compared to similar approaches. We also present current benchmarks of our production system, running on commodity out-of-the-box cloud Hadoop infrastructure, where the algorithm was deployed over a year ago, scaled to around 75 Billion nodes and 60 Billions linkages (and growing). We highlight the key aspects of our algorithm which enable seamless scaling and performance even in the presence of skewed data with large connected components in the size of 10 Billion nodes each.
翻译:使用分布式计算框架的大型图表处理正在行业中变得普遍和高效。 在这项工作中,我们展示了一个高度可缩放和可配置的构建连接组件的分布算法,称为Union Find Shuffle(UFS)和路径压缩。算法的规模和复杂程度取决于数据最初被分割的分区数量以及连接组件的大小。我们讨论了与类似方法相比的复杂性和基准。我们还介绍了我们生产系统的现有基准,它运行于一年多前已部署的商品箱外云中哈多普基础设施上,该算法被扩大至大约75亿个节点和60亿个连接(并正在增长 ) 。我们强调了我们的算法的关键方面,即使存在10亿个节点大小的大型连接组件的扭曲数据,也能够实现无缝的缩放和性。