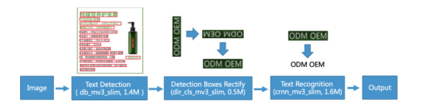
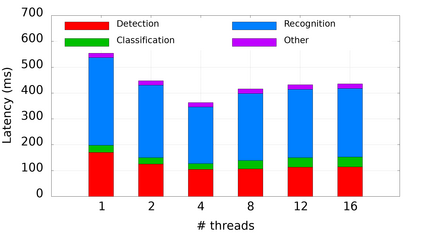
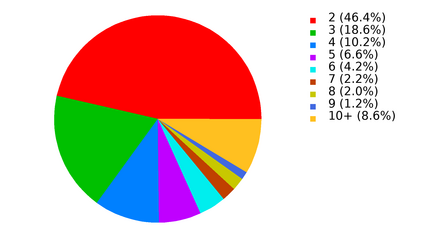
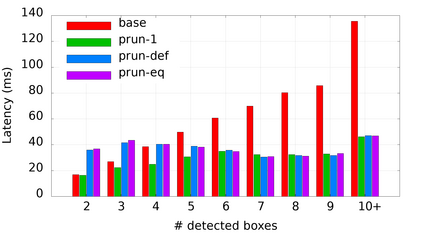
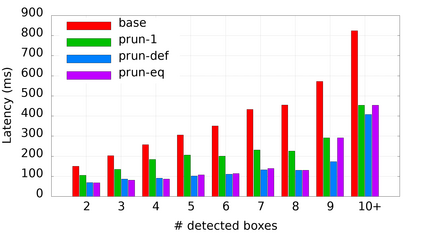
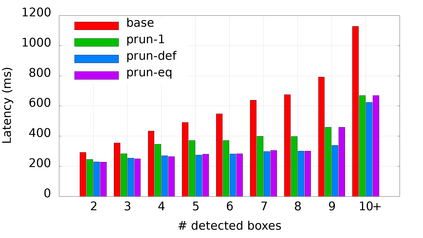
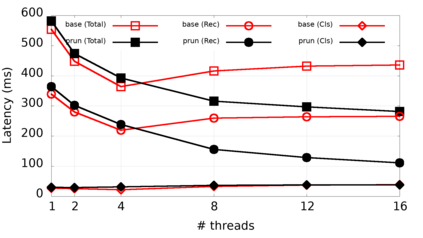
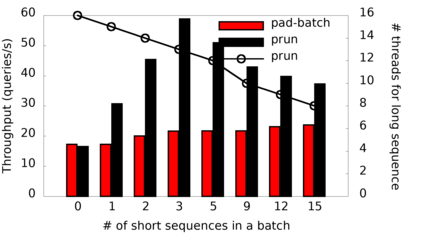
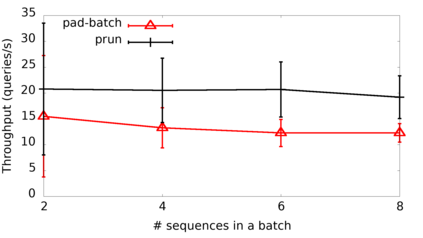
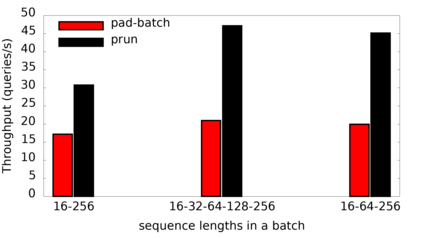
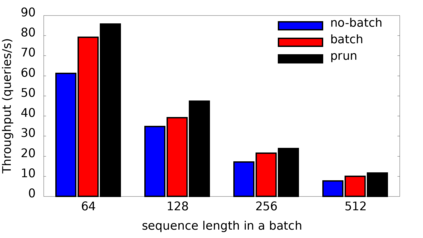
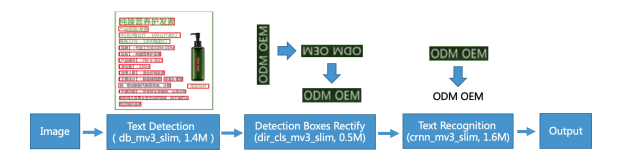
Many popular machine learning models scale poorly when deployed on CPUs. In this paper we explore the reasons why and propose a simple, yet effective approach based on the well-known Divide-and-Conquer Principle to tackle this problem of great practical importance. Given an inference job, instead of using all available computing resources (i.e., CPU cores) for running it, the idea is to break the job into independent parts that can be executed in parallel, each with the number of cores according to its expected computational cost. We implement this idea in the popular OnnxRuntime framework and evaluate its effectiveness with several use cases, including the well-known models for optical character recognition (PaddleOCR) and natural language processing (BERT).
翻译:许多流行的机器学习模式在使用CPU时规模不高。 在本文中,我们探讨了为什么基于众所周知的分化原则,提出一个简单而有效的方法来解决这一具有重大实际重要性的问题。考虑到推论,我们没有使用所有可用的计算资源(即CPU核心)来运行它,而是把工作分成可以平行执行的独立部分,每个部分都根据其预期计算成本与核心数量同步执行。我们在流行的OnnxRuntime 框架内实施这一想法,并用几个使用案例来评估其有效性,包括众所周知的光学识别模式(PaddleOCR)和自然语言处理模式(BERT)。