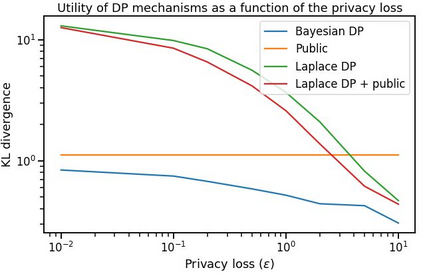
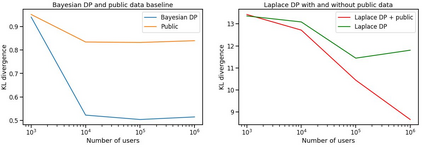
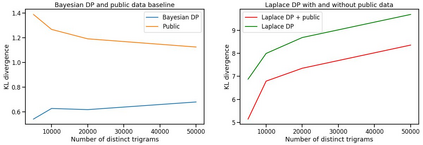
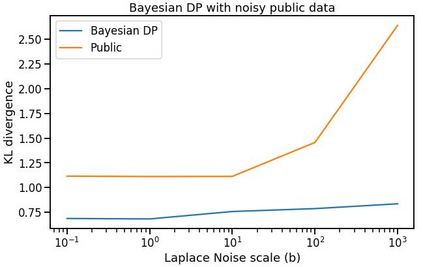
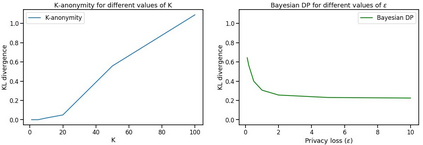
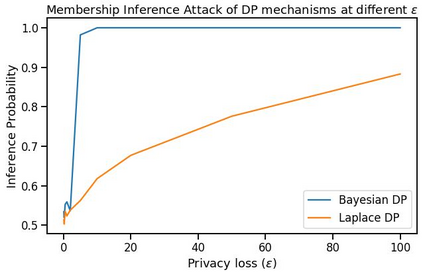
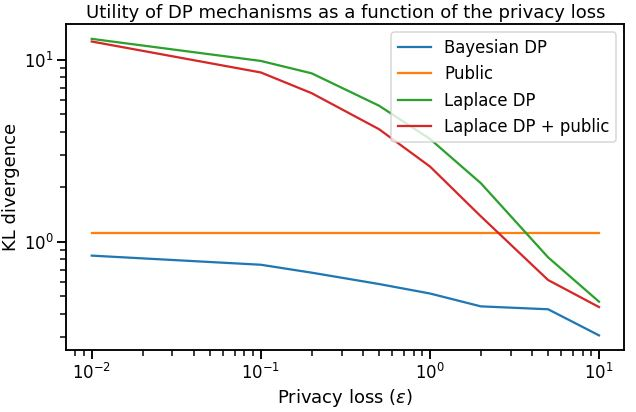
Differential privacy has gained popularity in machine learning as a strong privacy guarantee, in contrast to privacy mitigation techniques such as k-anonymity. However, applying differential privacy to n-gram counts significantly degrades the utility of derived language models due to their large vocabularies. We propose a differential privacy mechanism that uses public data as a prior in a Bayesian setup to provide tighter bounds on the privacy loss metric epsilon, and thus better privacy-utility trade-offs. It first transforms the counts to log space, approximating the distribution of the public and private data as Gaussian. The posterior distribution is then evaluated and softmax is applied to produce a probability distribution. This technique achieves up to 85% reduction in KL divergence compared to previously known mechanisms at epsilon equals 0.1. We compare our mechanism to k-anonymity in a n-gram language modelling task and show that it offers competitive performance at large vocabulary sizes, while also providing superior privacy protection.
翻译:与K-匿名等减少隐私的技术相比,在机器学习中,不同隐私作为一种强有力的隐私保障越来越受欢迎。然而,对正克计数应用不同的隐私大大降低了衍生语言模型的效用,因为其庞大的词汇库。我们提议采用不同隐私机制,将公共数据作为巴伊西亚结构的先期使用,以提供更严格限制隐私损失指标Epsilon,从而改进隐私-通用的权衡。它首先将计数转换为日志空间,接近作为高山的公共和私人数据的分布。然后对后方和软式数据进行评审,以产生概率分布。与普西隆以前已知的机制相比,这一技术实现了高达85%的KL差异,相当于0.1。我们将我们的机制与n-gram语言模拟任务中的k-匿名性作了比较,并表明它提供了大词汇规模的竞争性性表现,同时提供了更高级的隐私保护。