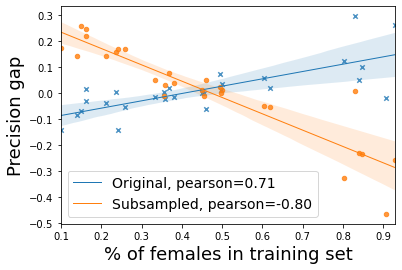
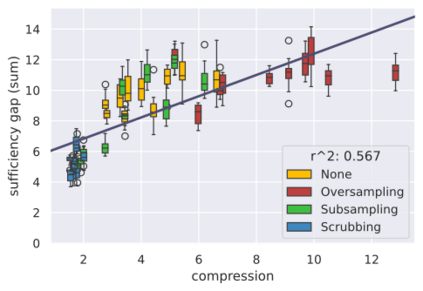
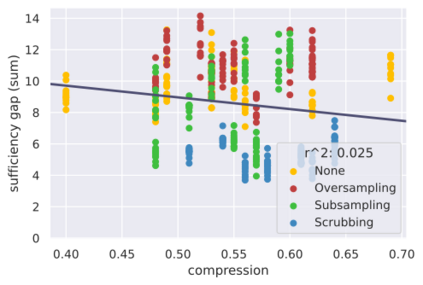
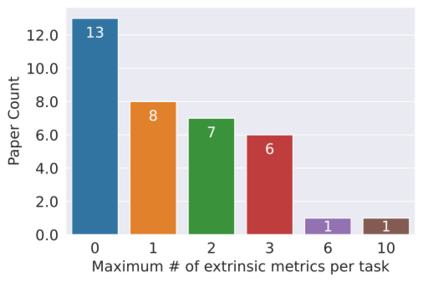
Considerable efforts to measure and mitigate gender bias in recent years have led to the introduction of an abundance of tasks, datasets, and metrics used in this vein. In this position paper, we assess the current paradigm of gender bias evaluation and identify several flaws in it. First, we highlight the importance of extrinsic bias metrics that measure how a model's performance on some task is affected by gender, as opposed to intrinsic evaluations of model representations, which are less strongly connected to specific harms to people interacting with systems. We find that only a few extrinsic metrics are measured in most studies, although more can be measured. Second, we find that datasets and metrics are often coupled, and discuss how their coupling hinders the ability to obtain reliable conclusions, and how one may decouple them. We then investigate how the choice of the dataset and its composition, as well as the choice of the metric, affect bias measurement, finding significant variations across each of them. Finally, we propose several guidelines for more reliable gender bias evaluation.
翻译:近年来,为衡量和减少性别偏见作出了相当大的努力,导致引入了大量的任务、数据集和衡量标准。在本立场文件中,我们评估了当前性别偏见评价的范式,并找出了其中的若干缺陷。首先,我们强调衡量模型在某些任务上的绩效如何受到性别影响的外部偏见衡量标准的重要性,而不是衡量模型表现的内在评价的重要性,这些评价与对与系统互动的人造成的具体伤害的联系不太紧密。我们发现,大多数研究中只测量了少数极端指标,尽管可以进行更多的衡量。第二,我们发现数据集和衡量标准往往相互结合,并讨论其组合如何阻碍获得可靠结论的能力,以及人们如何区分它们。然后我们调查数据集的选择及其组成,以及衡量标准的选择如何影响偏见的衡量,并发现每个数据之间的差异很大。最后,我们为更可靠的性别偏见评价提出了若干准则。