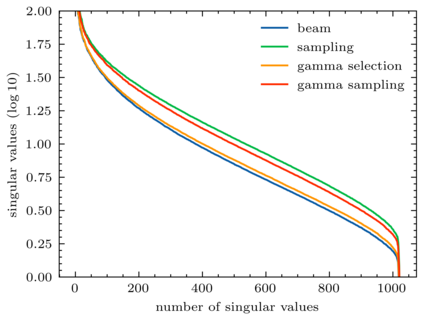
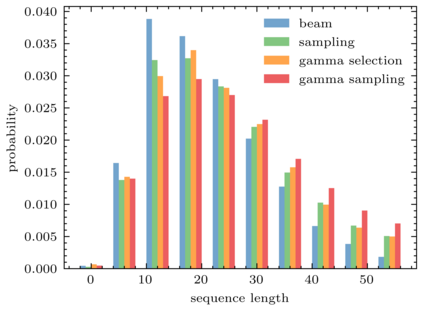
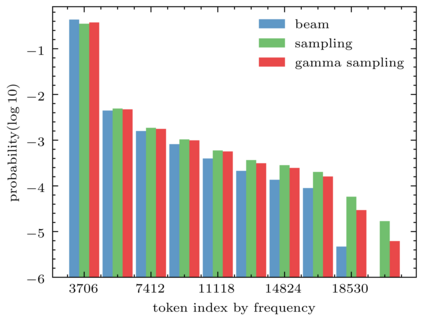
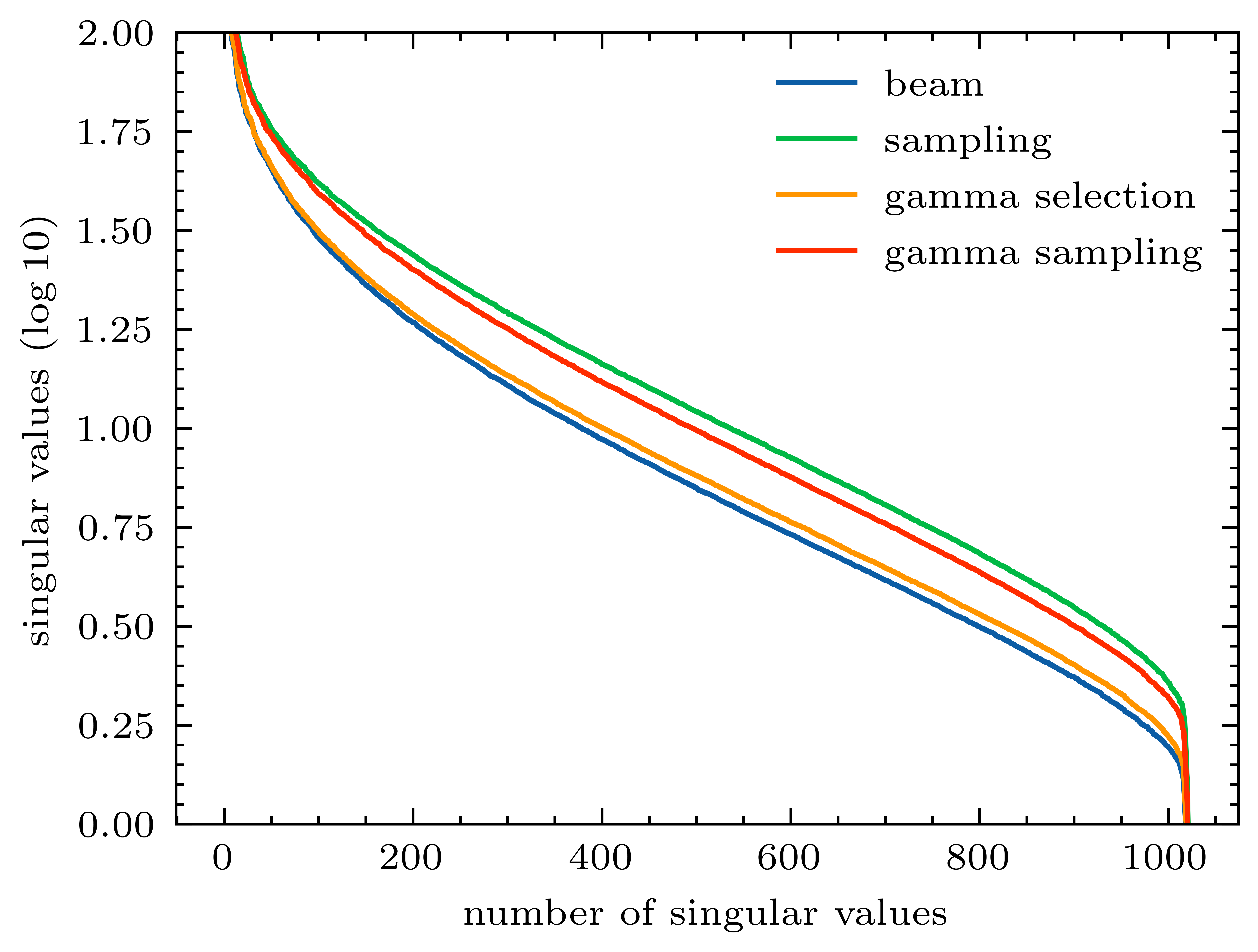
Back translation (BT) is one of the most significant technologies in NMT research fields. Existing attempts on BT share a common characteristic: they employ either beam search or random sampling to generate synthetic data with a backward model but seldom work studies the role of synthetic data in the performance of BT. This motivates us to ask a fundamental question: {\em what kind of synthetic data contributes to BT performance?} Through both theoretical and empirical studies, we identify two key factors on synthetic data controlling the back-translation NMT performance, which are quality and importance. Furthermore, based on our findings, we propose a simple yet effective method to generate synthetic data to better trade off both factors so as to yield a better performance for BT. We run extensive experiments on WMT14 DE-EN, EN-DE, and RU-EN benchmark tasks. By employing our proposed method to generate synthetic data, our BT model significantly outperforms the standard BT baselines (i.e., beam and sampling based methods for data generation), which proves the effectiveness of our proposed methods.
翻译:暂无翻译